[정리]analyzer를 사용한 수집 정보의 유사성 계산
요약
0. 수집 데이터는 기존 데이터와 완벽 매칭되는 것이 아닌 부분 데이터 검색 결과값이다.
1차 개선 : null 배제 후 유의미한 데이터 포집
2차 개선 : 유의미 데이터 중 overview - wiki_title 매칭하여 용어 변수 비교 (동음이의어, 잘못된 설명 제거로 신뢰성 향상)
3차 개선 : attraction_name - wiki_title의 매칭 값을 기존 결과(match_term에) 보정 값으로 추가 (상위 데이터셋 중 임의 데이터 200개 수기 분석 후 보정치 적용)
이를 통해 용어 일치 비율이 20% 이상 되는 값을 신뢰성 있는 데이터로 판단하여 제공하였다.
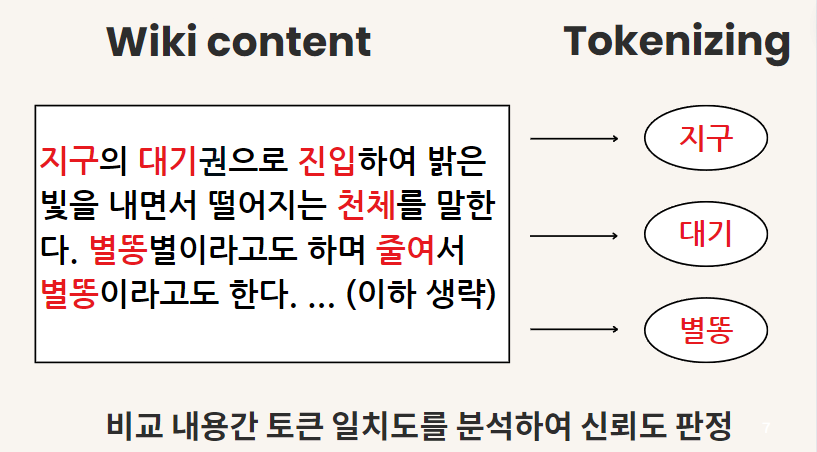
이를 도식화한다면 다음과 같다.

최초 문제 상황
현재 기본 공공데이터 API의 지명 이름(attraction_name)과, 수집할 데이터들의 명칭은 정확히 맞지 않는다.
따라서 해당 지명 이름으로 검색하면 유효한 검색결과가 대부분 나오지 않았다. (5% 이하의 정확도)
1. 최대한 정확하게 데이터 수집( 괄호, 공백, 유사 단어를 고려하여 검색 )
2. 지명과 연관된 데이터들을 수집
다음과 같은 목적을 위해 우리는 검색 과정에서 전처리 및 공백 어절 단위로 잘라 데이터를 수집했다.
< 예시 >
예를 들어 '설악산 국립공원' 이라는 attraction_name 이 존재했다면, 검색을 ' 설악산 국립공원 ', '설악산', '국립공원'의 세 가지 검색 결과를 검색하고 Elasticsearch에 저장하였다.
이 과정에서 검색 결과가 없다면 Null 상태로 저장되게 하였다.
검색 결과의 content가 상당수 연관된 정보이기는 하나, 동음이의어거나 전혀 상관이 없는 데이터의 경우도 있었다.
예를 들어 '유성' 이라고 하면 우리는 지명을 기대했지만, 유성(천문용어)가 나오는 경우도 있었다.
따라서 우리는 수집된 정보의 정확도를 기존 정보와 용어 단위로 비교하여 얼마나 유사한 값이 나오는지 분석했다.
기존 title의 추가 정보인 'overview'의 설명과, 해당 검색 결과의 설명인 'wiki_content'의 설명을 분석하여, 이를 term 단위로 쪼개 얼마나 매칭되는지를 확인했다.
[1차 개선] Null값 제거 및 처리
모든 도큐먼트를 순회하며 조회한 뒤, 쓸모없는 검색 결과(Null)을 처리할 것이다.
이를 통해 일차적으로 API 요청, 혹은 검색 시 결과가 없는 영양가 없는 정보는 제거하고 제공할 수 있을 것이다.
만약 'wiki_content'가 null인 경우라면 기존 데이터의 attraction_name을 쪼갠 부분 검색의 스크래핑 검색 결과가 없는 것이다.
해당 검색 결과가 없으므로, match와 total 수치를 전부 1, -1로 넣을 것이다. (결과적으로 음수 값이 반환된다)
total_term : overview와 wiki_content의 내용을 분석기를 통해 토크나이징한 용어의 합
match_term : 이 전체 용어들 중 overview의 term과 wiki_content의 term이 일치하는 개수
우리 데이터에서는 wiki_content가 null인 경우가 많이 존재한다(스크래핑 과정에서 유효한 값이 많지 않았기 때문이다.)

이런 빈 값들을 Description으로 추천할 수는 없다.
/**
* 해당 도큐먼트의 content 값이 Null인지 판정 후, true라면 term 값을 update하는 메서드
* @param wiki
* @return boolean
*/
public boolean checkWikiConentIsNull(Wiki wiki) {
try {
String wikiContent = wiki.getWiki_content();
if(wikiContent == null || wikiContent.equals("null")) {
wiki.setMatchTerm(-1); //null을 뜻하는 -1 삽입
wiki.setTotalTerm(1);
wikiServiceBasic.insertWiki(wiki); //변경된 값으로 갱신
return true;
}
return false; //아니라면 false 반환
} catch (Exception e) {
throw new CommonException(ExceptionType.CHANGE_NULL_TERMS_NO_WIKICONTENTS_FAIL);
}
}

[2차 개선]

위와 같은 문제 상황을 해결하기 위해 내용을 토큰화한 후, 비교를 통해 신뢰성 있는 데이터를 가릴 것이다.
전체 용어에 비해 유효한 용어의 비율의 수치를 가질 total_term과 match_term 필드를 추가하였다.
1. 토큰화 : 문자열을 입력받아 분석기 사용 후 토큰화하는 메서드
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.11/java-rest-high-analyze.html
Analyze API | Java REST Client [7.11] | Elastic
Asynchronous executionedit Executing a AnalyzeRequest can also be done in an asynchronous fashion so that the client can return directly. Users need to specify how the response or potential failures will be handled by passing the request and a listener to
www.elastic.co
가장 먼저, 토큰화 과정이 필요하다. 우리가 비교로 하는 overview 필드나, content 필드 전부 문장으로 되어있다.
해당 문장을 입력하면, 해당 인덱스에 매핑된 분석기를 통해 토큰화하고, 이를 HashMap<용어, 개수> 형태로 저장한다.
인덱스에 존재하는 비교용 Analyzer를 AnalyzeRequest를 통해 가져와 비교 후 HashMap형태로 저장하였다.
private final RestHighLevelClient restHighLevelClient;
//2단어 길이 이상 필터링된 인덱스
@Value("${info.index.wiki.gt-two-token}")
String twoIndex;
@Value("${info.analyzer.nori}")
String noriAnalyzer;
public HashMap<String, Integer> useAnalyzer(String inputString, HashMap<String, Integer> hashMap) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer(twoIndex, noriAnalyzer, inputString);
AnalyzeResponse response = restHighLevelClient.indices().analyze(request, RequestOptions.DEFAULT);
List<AnalyzeResponse.AnalyzeToken> tokens = response.getTokens(); // 결과에서 토큰화된 텍스트 가져오기
// tokens 리스트를 반복하여 HashMap에 저장 후 출력
tokens.forEach(token -> {
String term = token.getTerm();
log.info("[useAnalyzer] Term 정보 : {}", term);
if(hashMap.containsKey(term)) {
hashMap.put(term, hashMap.get(term) + 1);
}
else hashMap.put(term, 1);
});
return hashMap;
}
예를 들어 "여수 밤바다는 바다 중 제일 유명하다." 라는 문장이 있으면 '바다', '여수', '유명', '제일' 이 토큰화된다.
물론, 개수 역시도 포함한다.
2. 유사 Term 비교
이전 과정에서 'overview' 의 문장과, 'content'의 문장을 각각 hashmap의 형태로 변환했다.
overview의 경우 우리가 가지고 있는 유의미한 관광지 설명을 의미하고, content의 경우 타이틀 검색을 통해 수집한 데이터의 설명이다.
이를 Input으로 받아 서로간의 term이 얼마나 일치하는지, 전체 term은 몇 개인지 확인하는 메서드를 확인해야 한다.
/**
* <용어, 개수>의 해시맵 두개를 받아, 각각의 용어간 유사성 빈도 비교
* @param hashMapA
* @param hashMapB
* @return
*/
public int[] calculateTermOverviewAndContent(HashMap<String, Integer> hashMapA, HashMap<String, Integer> hashMapB) {
try {
int totalTermCount = 0; //전체 용어 수
int matchTermCount = 0; //맞는 용어 수
//1. 전체 토큰 세기 : HashMap의 values() 메서드를 사용하여 값들을 순회하고 합산
for (Integer value : hashMapA.values()) {
totalTermCount += value;
}
for (Integer value : hashMapB.values()) {
totalTermCount += value;
}
//2. 맞는 용어 수를 세기
for(String key : hashMapA.keySet()) {
if(hashMapB.containsKey(key)) {
// log.info("[calculateSimilarityByTerm] 동일 Key값 : ", key);
matchTermCount += hashMapA.get(key);
matchTermCount += hashMapB.get(key);
// log.info("[calculateSimilarityByTerm] A.get : {} + B.get : {} ", hashMapA.get(key), hashMapB.get(key));
}
}
log.info("[calculateSimilarityByTerm] 전체 용어 : {} , 매치된 용어 : {}", totalTermCount, matchTermCount);
return new int[] {totalTermCount, matchTermCount};
} catch (Exception e) {
throw new CommonException(ExceptionType.CALCULATE_SIMILARY_TERMS);
}
}
해당 로직을 통해 HashMap 형태로 변환한 두 문장의 결과값들을 비교하고, 전체 카운팅을 반환할 수 있다.
테스팅 결과(동음이의어)

아래 설명을 보면 393개의 전체 용어 중 일치율은 17개에 그친다.
실제로 동음이의어였지만, 전혀 다른 지명의 설명들이었기에 상대적으로 낮은 일치율임을 확인할 수 있다.
테스팅 결과(유사 단어)
비슷한 경우도 살펴보겠다.
원래 지명은 '남산서울타워 한복문화체험관'이었고, 검색 결과는 '남산서울타워'이다.


상대적으로 정확한 로직임을 측정할 수 있다.
최악의 상황을 가정한, 가장 긴 String 구문을 용어화해서 실행한 결과 135ms의 검색 속도를 보인다. (Postman 전송까지는 267ms)
이 정도면 실제 서비스에서도 충분히 사용할만한 수치라고 생각한다. 이 정확도를 ElasticSearch에 스코어링으로 추가할 것이다.
[3차 개선] AttractionName - Content 보정치 추가
3차 개선 : attraction_name - wiki_title의 매칭 값을 기존 결과(match_term에) 보정 값으로 추가 (상위 데이터셋 중 임의 데이터 200개 수기 분석)
우리가 수집한 'wiki_content'와 문서 제목인 'attraction_name'과의 연관도도 보정치에 추가해야 하지 않냐는 팀원의 의견이 있었다.
포집한 데이터 중 약 300 ~ 400여개의 데이터를 수기로 확인하였고, 일정 부분의 연관성을 찾아낼 수 있었다.

BM25 알고리즘이 총 문서에서 용어 포함 개수를 로그함수로 계산하는 것처럼, 우리 역시 제목과 매칭되는 용어 개수, 내용 간 중첩된 용어 개수를 종합적으로 비교하여 20% 이상 유사할 경우 해당한다는 결론을 내렸다.
제목 연관성을 추가하여 기존 용어 카운트에 보정치로 추가하였다.
public void updateNewTerms(Wiki wiki) {
try {
//1차 비교 : overview : wiki_content
int termsOne[] = calculateTermOverviewAndContent(
useAnalyzerAndGetTokens(wiki.getOverview()),
useAnalyzerAndGetTokens(wiki.getWiki_content())
);
//2차 비교 : attraction_name과(원문 타이틀) wiki_content
int termsTwo[] = calculateTermOverviewAndContent(
useAnalyzerAndGetTokens(wiki.getAttractionName()),
useAnalyzerAndGetTokens(wiki.getWiki_content())
);
//예외 처리 : divideByZero, 혹은 유의미한 토큰이 없을 경우 Null과 동일 처리
if(termsOne[0] == 0 || termsTwo[0] == 0) {
wiki.setMatchTerm(-1); //null을 뜻하는 -1 삽입
wiki.setTotalTerm(1);
wikiServiceBasic.insertWiki(wiki); //변경된 값으로 갱신
return;
}
//2차가 전체 용어가 적을 수밖에 없다. 전체 용어 개수만큼 비율을 맞추고, matchTerm만 추가해준다.
int correctionFactor = termsOne[0] / termsTwo[0]; //보정치
int totalMatchTerm = termsOne[1] + (correctionFactor * termsTwo[1]);
System.out.println("1차 : " + termsOne[0] + " " + termsOne[1]);
System.out.println("2차 : " + termsTwo[0] + " " + termsTwo[1] + " : 보정치 " + totalMatchTerm);
} catch (Exception e) {
throw new CommonException(ExceptionType.UPDATE_NULL_TERMS_FAIL);
}
}