[ElasticSearch] 집계함수 정의와 적용
PUT _index_template/scrap_template_wiki
{
"index_patterns" : [
"scrap_wiki_*"
],
"template" : {
"settings" : {
"index" : {
"analysis" : {
"filter" : {
"length_filter": {
"type": "length",
"min": 2
},
"nori_filter" : {
"type" : "nori_part_of_speech",
"stoptags" : [
"E",
"IC",
"J",
"MAG",
"MM",
"NA",
"NR",
"SC",
"SE",
"SF",
"SH",
"SL",
"SN",
"SP",
"SSC",
"SSO",
"SY",
"UNA",
"UNKNOWN",
"VA",
"VCN",
"VCP",
"VSV",
"VV",
"VX",
"XPN",
"XR",
"XSA",
"XSN",
"XSV"
]
}
},
"analyzer" : {
"korean" : {
"filter" : [
"nori_readingform",
"nori_filter",
"length_filter"
],
"type" : "custom",
"tokenizer" : "nori_tokenizer"
}
}
},
"number_of_shards" : "1"
}
},
"mappings" : {
"properties" : {
"number" : {
"type" : "keyword"
},
"wiki_content" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"overview" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"pk_id" : {
"type" : "keyword"
},
"attraction_name" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"content_id" : {
"type" : "keyword"
},
"wiki_title" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"id" : {
"type" : "keyword"
}
}
}
}
}개요
집계함수를 통해 마치 SQL의 group by와 같이 그룹별 통계를 낼 수 있다.
간단한 예문을 통해 먼저 집계함수를 알아보자.
집계 요청-응답 형태
집계를 위한 특별한 API가 제공되는 것은 아니다. 요청 본문에 aggs 파라미터를 이용하면 결과에 대한 집계를 생성할 수 있다.
GET 인덱스/_search
{
"aggs": {
"my_aggs": { //사용자가 지정하는 집계 이름
"agg_type": { //집계 타입. ES에서는 크게 metric agg와 bucket aggs를 제공
...
}
}
}
}
//결과
{
...
"hits" : {
"total" : {
...
},
"aggregations" : {
"my_aggs" : {
"value" :
}
}
}메트릭 집계
기존 sql의 통계 함수처럼, 평균 최대 합계 등 .. 통계 결과를 보여준다.
| 매트릭 집계 | 설명 |
|---|---|
| avg | 평균값 계산 |
| min | 최소 |
| max | 최대 |
| sum | 총합 |
| percentiles | 백분위 퍼센테이지 |
| stats | 필드의 min, max, sum, avg, count를 한 번에 볼 수 있다. |
| cardinality | 필드의 유니크한 값 개수를 확인 |
| geo-centroid | 필드 내부 위치 정보의 중심점을 계산 |
버킷 집계
메트릭 집계가 특정 필드의 통계 수치를 계산하는 용도라면, 버킷 집계의 경우 특정 기준에 맞추어 도큐먼트를 그룹핑한다.
버킷은 도큐먼트가 분할되는 단위의 각 그룹을 나타낸다.
| 버킷 집계 | 설명 |
|---|---|
| histogram | 숫자 타입 필드를 일정 간격으로 분류한다. |
| data_histogram | 날짜/시간 타입 필드 분류 |
| range | 숫자 타입 필드 범위 분류 |
| date_range | 날짜/시간타입 필드 범위 분류 |
| terms | 용어 기준 분류 |
| significant_terms | term 버킷과 유사하나, 인덱스 내 문서 대비 통계적으로 유의미한 값들을 기준으로 분류 |
| filters | 문서의 조건을 직접 지정 |
사용 이슈
keyword 필드 사용
현재 데이터 상으로는 wiki_content.keyword 등과 같이 키워드 단위로 검색해야 한다.
하지만 이 경우 원했던 토큰 추출이 불가능하다.
fielddata=true 설정을 통해 text 필드에 대한 집계를 강제로 활성화할 수 있다. 하지만 이 설정은 권장되지 않는데, 역색인을 'uninverting' 하는 과정이 많은 양의 메모리를 사용할 수 있기 때문이다. 만약 많은 양의 데이터를 다루는 경우, 이 방법은 성능 저하를 초래할 수 있다.
fielddata 옵션이 많은 메모리 부하를 일으키지만, 그럼에도 nori를 사용하여 토크나이징한 값들을 집계해서 키워드를 추출해야 한다..
그래서 일단 csv 복사해서, tdata 인덱스에서 실험해보았다.
PUT /index1106_tdata
{
"settings": {
"number_of_shards": 1,
"analysis": {
"analyzer": {
"korean": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["nori_readingform"]
}
}
}
},
"mappings": {
"properties" : {
"id" : {"type" : "keyword"},
"content_id" : {"type" : "keyword"},
"pk_id" : {"type" : "keyword"},
"number" : {"type" : "keyword"},
"attraction_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"wiki_title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"wiki_content" : {
"type" : "text",
"fielddata": true,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}wiki_content의 fielddata 를 true로 설정할 것이다.
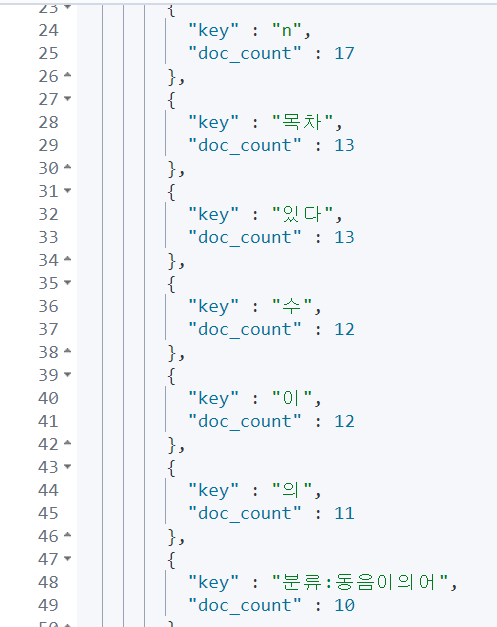

시간은 생각보다 양호하였으나, 결과 역시 예상보다 답이 없다. 이 방법으로는 실행하기 힘들 것이다.
Nori 불용어 제거
[nori tokenizer에서 불용어 제거
nori에서 기본적으로 검색할 때 "조사", "어미", "감탄사" 등 검색에 불필요한 단어도 모두 형태소 분석이 된다. 형태소 분석이 불필요한 불용어를 설정해보자. "사랑하다"를 nori로 형태소 분석을
rudaks.tistory.com](https://rudaks.tistory.com/entry/nori-tokenizer%EC%97%90%EC%84%9C-%EB%B6%88%EC%9A%A9%EC%96%B4-%EC%A0%9C%EA%B1%B0)
https://coding-start.tistory.com/167
[Elasticsearch - 4.한글 형태소분석기(Nori Analyzer)
엘라스틱서치 혹은 솔라와 같은 검색엔진들은 모두 한글에는 성능을 발휘하기 쉽지 않은 검색엔진이다. 그 이유는 한글은 다른 언어와 달리 조사나 어미의 접미사가 명사,동사 등과 결합하기
coding-start.tistory.com](https://coding-start.tistory.com/167)
지금껏 분석기에 불용어를 제거하지 않았다는 점을 깨달았다. 불용어를 제거해보고자 한다.
노리에서 제공하는 불용어 필터를 추가해주었다.
PUT nori_test
{
"settings": {
"number_of_shards": 1,
"analysis": {
"analyzer": {
"korean": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["nori_readingform", "nori_filter"]
}
},
"filter" : {
"nori_filter": {
"type": "nori_part_of_speech",
"stoptags": [
"E",
"IC",
"J",
"MAG",
"MM",
"NA",
"NR",
"SC",
"SE",
"SF",
"SH",
"SL",
"SN",
"SP",
"SSC",
"SSO",
"SY",
"UNA",
"UNKNOWN",
"VA",
"VCN",
"VCP",
"VSV",
"VV",
"VX",
"XPN",
"XR",
"XSA",
"XSN",
"XSV"
]
}
}
}
}
}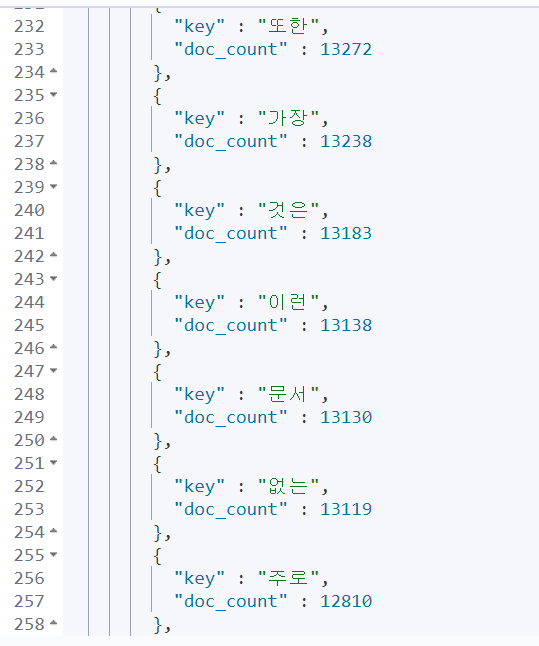
이 방법으로는 키워드 추출이 불가능할 것 같다. 다른 방법을 찾아보아야 한다.
(11.07) 문제 해결
문제의 원인을 찾은 것 같다.
analyzer가 적용되지 않은 값이 출력되었던 것이다.
이는 너무나도 간단한 문제였는데, Setting에 분석기 잘 넣고 mappings에 분석기를 적용하지 않았다..
settings에서 analyzer가 정의되어 있다고 해서 모든 텍스트 필드에 자동으로 적용되는 것은 아니다.
analyzer를 적용하려면 mappings에 해당 필드를 정의할 때 명시적으로 지정해주어야 한다. settings에서 analyzer를 정의하는 것은 그것을 사용할 수 있도록 Elasticsearch에 알리는 것이고, 실제로 그 analyzer를 어떤 필드에 사용할지는 mappings에서 결정한다.
# 예를 들어 이런 식으로.. 지금껏 잘못 설정했다.
"wiki_content": {
"type": "text",
"analyzer": "korean",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}


정리
그러니까 추가하자면, 나는 인덱스 내에 특정 필드(wiki_content)에서 특정 용어가 몇 개 나오는지 많이 나오는 순서대로 집계하고 싶다. 그렇기에 fieldData를 추가했다.
하지만 이 text의 토크나이저 과정에서 korean analyzer가 적용되지 않은 것 같다!
( 동일 구문이지만 analyzer test의 결과와 다른듯 했다.).
이 이유는 내가 mapping 과정에서 wiki_content의 세부 설정에서 'analyzer'를 추가하지 않았던 것으로 판단된다.
이 경우 인덱스 템플릿을 수정하고, 분석기 설정을 추가해야 한다.
11.08 추가 변경 : 인덱싱 전 처리 추가 (min_token_length)
토크나이저된 단어들, 분석기를 통해 불용어를 최대한 제거해도 한 글자 단위의 용어들은 그다지 쓸모가 없다.
분석기 설정에서 애초에 한 글자 단어들을 제외하려고 한다.
Elasticsearch에서 min_token_length를 사용해 한 글자 토큰을 배제하려면, 사용자 정의 토크나이저를 설정할 때 해당 옵션을 사용해야 한다.
기존 내 nori 분석기의 인덱스 템플릿을 다음과 같이 변경할 것이다.
{
"settings": {
"index": {
"analysis": {
"filter": {
"length_filter": {
"type": "length",
"min": 2
},
// 나머지 필터 설정...
},
"analyzer": {
"korean": {
"tokenizer": "nori_tokenizer",
"filter": [
"nori_readingform",
"nori_filter",
"length_filter" // 여기에 추가
]
}
}
// 나머지 분석기 설정...
}
}
// 나머지 인덱스 설정...
}
// 매핑 설정...
}
총 값은 다음과 같다.
PUT _index_template/scrap_template_wiki
{
"index_patterns" : [
"scrap_wiki_*"
],
"template" : {
"settings" : {
"index" : {
"analysis" : {
"filter" : {
"length_filter": {
"type": "length",
"min": 2
},
"nori_filter" : {
"type" : "nori_part_of_speech",
"stoptags" : [
"E",
"IC",
"J",
"MAG",
"MM",
"NA",
"NR",
"SC",
"SE",
"SF",
"SH",
"SL",
"SN",
"SP",
"SSC",
"SSO",
"SY",
"UNA",
"UNKNOWN",
"VA",
"VCN",
"VCP",
"VSV",
"VV",
"VX",
"XPN",
"XR",
"XSA",
"XSN",
"XSV"
]
}
},
"analyzer" : {
"korean" : {
"filter" : [
"nori_readingform",
"nori_filter",
"length_filter"
],
"type" : "custom",
"tokenizer" : "nori_tokenizer"
}
}
},
"number_of_shards" : "1"
}
},
"mappings" : {
"properties" : {
"number" : {
"type" : "keyword"
},
"wiki_content" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"overview" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"pk_id" : {
"type" : "keyword"
},
"attraction_name" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"content_id" : {
"type" : "keyword"
},
"wiki_title" : {
"fielddata" : true,
"analyzer" : "korean",
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"id" : {
"type" : "keyword"
}
}
}
}
}