부하 증가에 따른 로드 밸런싱 정책 고려 (Envoy) (24.06.20)
개요
현재 자체적으로 개발한 Collector 서버에서 수집하는 데이터가 많아질 때면, OOM이 발생하고는 한다.
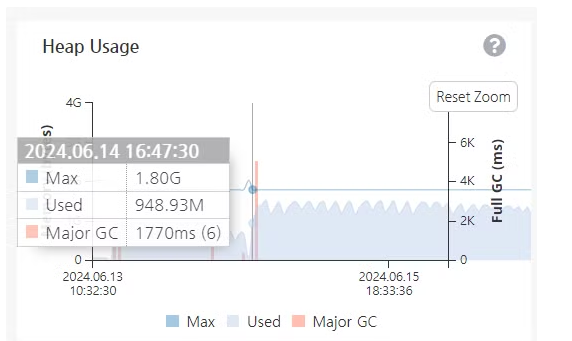
(특히 수집하는 타겟 서버에서 갑자기 많은 부하가 일어날 경우, 급작스러운 데이터 증가로 인해 발생하는 일이다.)
Major GC를 막을 수는 없지만(자연스러운 현상이니), 문제는 ‘갑작스럽게 허용 수치 이상의 많은 데이터가 들어올 경우 서버가 멈춰버리는 빈도가 꽤 커진다는 것.

이를 위해 Memory Leak 등을 측정하고자 MAT로 힙 덤프를 떠서 분석했었지만, 근본적으로 막을 수 없는 JPA 관련 인스턴스나 캐시 등은 어쩔 수가 없다 (Query Cashe Plan이나.. 기본적으로 매핑에 사용되는 준비된 persistEntity 등.. ). 서버의 멈춤 현상을 막기 위해 할 수 있는 건 사실 단순하다.
고가용성(HA)을 올리는 것이다.
이를 위해 먼저 로드밸런서를 두고, 다수의 인스턴스를 분리하여 실행하기로 결정했다.

사실 이 구역 대빵은 Nginx지만, 큰 문제점이 있다.
현재 .grpc 프로토콜로 데이터를 수신하기에 Nginx+를 사용해야 하며 (기본 버전은 Http 1.1버전까지만 지원하는 듯 하다.) 이는 오픈 소스가 아니라 상업용 플랜이라는 것이다.
이를 해결하기 위해 ‘envoy’를 사용하여 로드 밸런싱을 진행하였다.
4317 포트로 받은 뒤, 각각 인스턴스를 나누어 9999, 9998, 9997 .. 로 세분화 할 것이다.
Yaml
static_resources:
listeners:
- name: listener_0
address:
socket_address:
address: 0.0.0.0
port_value: 4317
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match: { prefix: "/", grpc: {} }
route:
cluster: service_backend
timeout: 0s
http_filters:
- name: envoy.filters.http.router
http2_protocol_options: {} # HTTP/2 enable
clusters:
- name: service_backend
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
http2_protocol_options: {} # GRPC use HTTP/2
load_assignment:
cluster_name: service_backend
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 10.50.10.145
port_value: 9999
- endpoint:
address:
socket_address:
address: 10.50.10.145
port_value: 9998
- endpoint:
address:
socket_address:
address: 10.50.10.145
port_value: 9997
admin:
access_log_path: "/opt/chshin/envoy/admin_access.log"
address:
socket_address:
address: 0.0.0.0
port_value: 8001
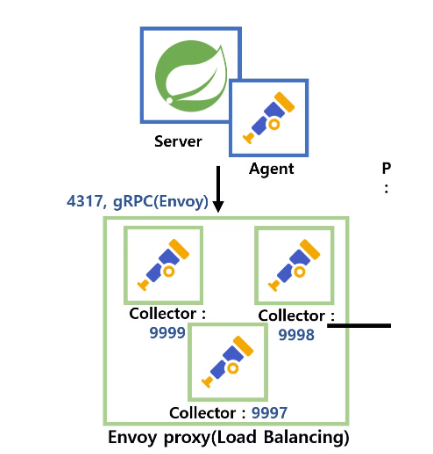
.. 이와 같은 형식으로 수집기의 부하를 줄일 수 있다.
위의 도표와 달리 현재는 5개의 서버에서 계측 데이터를 수집하는 형태이다.
결과
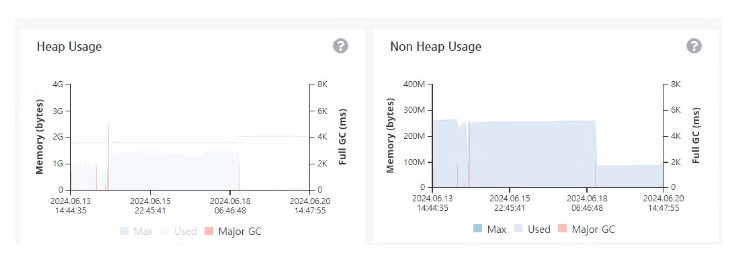
18일 사용 기점으로 급격하게 떨어진 부하의 모습이 보인다.
추가적으로 올린 인스턴스는 처음부터 안정적으로 동작하는 모습이다.
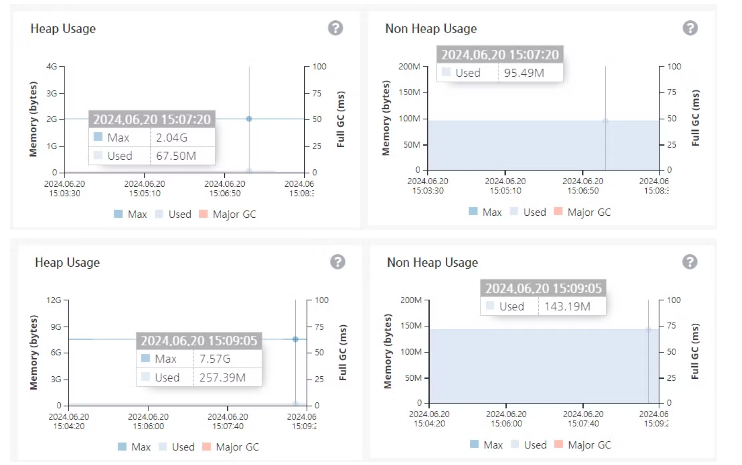
1번같은 경우는 257M를 소모하는데, 이건 추가적으로 로드밸런서가 아닌 Direct API로 데이터를 넣어주는 로직 때문일 가능성이 크다.
어쨌든 중요한건 GC가 발생하지 않을 정도로 안정적으로 동작했다는 것.