Eclipse MAT 전체 Heap 사용량 보기 / 메모리 분석 (24.06.18)
현재 온보딩중인 서버의 Memory Leak을 보기 위해 heap dump를 뜬 뒤, 분석한 overview 값과 실제 APM 및 프로세스 상의 JVM Heap Used가 일치하지 않는다.

MAT의 Heap Overview 294.1MB

하지만 Pinpoint 및 외부 APM의 경우 한결같이 600-700MB의 Heap 사용을 이야기하고 있다.
이렇게 차이가 날 이유가 없는데.. 실제로 검색을 조금 해본 결과, 다음과 같은 설정을 해주지 않아서 벌어진 문제였다.
문제 원인 및 해결 방법
1. Eclipse MAT 설정 변경
MAT에서 기본적으로 도달할 수 없는 객체는 분석에 포함되지 않는다. 이를 포함하려면 설정을 변경해야 한다.
- MAT 실행:
- Eclipse Memory Analyzer (MAT)를 실행한다.
- Preferences 열기:

- 메뉴에서 Window > Preferences를 선택한다.

- Memory Analyzer 설정:
- Preferences 창에서 Memory Analyzer 섹션으로 이동한다.
- Keep unreachable objects 옵션을 체크한다.
- 이 옵션을 체크하면 힙 덤프 파일을 다시 로드할 때 도달할 수 없는 객체도 포함된다.

2. 힙 덤프 파일 다시 로드
설정을 변경한 후, 기존 힙 덤프 파일의 인덱스를 삭제하고 다시 로드해야 한다.
힙 덤프 파일 인덱스 삭제:

- 힙 덤프 파일 인덱스 삭제:
- Window > Heap Dump History를 선택하여 힙 덤프 파일 목록을 연다.
- 분석하려는 힙 덤프 파일을 오른쪽 클릭하고 Delete Index Files를 선택하여 인덱스를 삭제한다.

- 힙 덤프 파일 다시 열기:
- 힙 덤프 파일을 다시 열어 인덱스를 새로 생성한다.
- 이제 설정된 옵션에 따라 도달할 수 없는 객체도 포함되어 분석된다.
3. Unreachable Objects 확인
도달할 수 없는 객체를 포함하여 분석한 후, 해당 객체들을 확인할 수 있다.
- Unreachable Objects Histogram 확인:
- 힙 덤프 파일을 열면 Overview 탭에서 Unreachable Objects Histogram을 확인할 수 있다.
- 이 히스토그램은 도달할 수 없는 객체의 크기와 수를 보여준다.
- GC Roots와 도달할 수 없는 객체:
- Java Basics > GC Roots 쿼리를 실행하여 도달할 수 없는 객체를 포함한 힙 덤프를 분석한다.
- Unreachable Objects 행을 선택하고, Show Retained Set 쿼리를 실행하여 도달할 수 없는 객체들의 히스토그램을 확인할 수 있다.

정확히 동일한 값의 데이터를 수집할 수 있게 되었다!
Eclipse MAT에서 '도달할 수 없는 객체(Unreachable Objects)'의 의미와 이유
1. '도달할 수 없는 객체'란?
'도달할 수 없는 객체(Unreachable Objects)'는 가비지 컬렉션(GC)에 의해 더 이상 참조되지 않으며, 따라서 다음 GC 사이클에서 제거될 객체들이다. 이러한 객체들은 프로그램 실행 중 더 이상 사용되지 않기 때문에 GC 루트에서 접근할 수 없다.
2. 기본적으로 나타나지 않는 이유
Eclipse MAT는 기본적으로 '도달할 수 없는 객체'를 분석에서 제외한다. 이는 몇 가지 이유 때문이다.
- 성능 최적화: 도달할 수 없는 객체를 포함하면 분석 시간과 메모리 사용량이 증가할 수 있다.
- 실제 유효한 데이터 초점: MAT는 주로 현재 프로그램이 사용하는 실제 메모리와 관련된 유효한 객체를 분석하는 데 초점을 맞춘다. 도달할 수 없는 객체는 이미 GC에 의해 제거될 예정이므로, 기본적으로는 분석에 포함되지 않는다.
3. '도달할 수 없는 객체' 포함 시의 의미
도달할 수 없는 객체를 포함하여 분석하면, 메모리 누수(leak)나 불필요한 메모리 사용에 대한 더 정확한 정보를 얻을 수 있다. 특히 메모리 누수를 찾고자 할 때, 이러한 객체들을 분석하는 것이 중요하다.
4. '도달할 수 없는 객체'를 포함하는 방법
앞서 설명한 바와 같이, 설정을 통해 도달할 수 없는 객체를 포함하여 분석할 수 있다.
ref :
https://bugs.eclipse.org/bugs/show_bug.cgi?id=543045
2. 분석
도달할 수 없는 객체를 포함한 힙 덤프 분석 설정을 완료했다면, 이제 메모리 누수를 찾기 위해 분석을 시도해 보자.
1. 힙 덤프 파일 열기
- 설정을 변경하고 도달할 수 없는 객체를 포함하여 힙 덤프 파일을 다시 열었으면, 이제 힙 덤프 파일에서 메모리 누수를 분석할 수 있다.
2. Leak Suspects Report 실행
MAT는 메모리 누수를 자동으로 탐지하고 보고하는 기능을 제공한다. 이 기능을 사용하여 메모리 누수를 쉽게 식별할 수 있다.
- Leak Suspects Report 실행:
- Reports > Leak Suspects를 선택한다.
- 이 보고서는 메모리 누수가 의심되는 객체들을 자동으로 탐지하고, 누수가 발생할 가능성이 높은 경로를 보여준다.
- Leak Suspects 분석:

- 보고서에서 메모리 누수가 의심되는 객체들을 확인한다.
- 각 객체에 대해 어떤 경로를 통해 누수가 발생하는지 확인할 수 있다.
이 메시지는 Eclipse MAT의 Leak Suspect Report에서 나온 결과로, 다음 두 가지 중 하나일 가능성이 높다.
- 비즈니스 로직에서 HashMap을 많이 사용하거나,
- JVM의 기본 클래스로더에 의해 HashMap 클래스 인스턴스가 많이 로드되거나.
하지만, 실제로 인스턴스를 많이 생성한 것은 애플리케이션의 비즈니스 로직일 가능성이 높다.
아래의 Dominator Tree를 실제로 분석해보자.
3. Dominator Tree 분석
Dominator Tree는 메모리 사용량이 많은 객체와 그 객체들이 참조하는 하위 객체들을 시각적으로 보여준다. 이를 통해 메모리 누수를 유발하는 주요 객체들을 식별할 수 있다.
- Dominator Tree 열기:
- Dominator Tree 탭을 열고, 메모리 사용량이 많은 객체들을 확인한다.
- 메모리 사용량 분석:
- 메모리 사용량이 높은 객체들을 중심으로 분석하여, 어떤 객체들이 가장 많은 메모리를 차지하고 있는지 확인한다.
- 특정 객체가 예상보다 많은 메모리를 차지하고 있다면, 해당 객체가 메모리 누수의 원인일 수 있다.
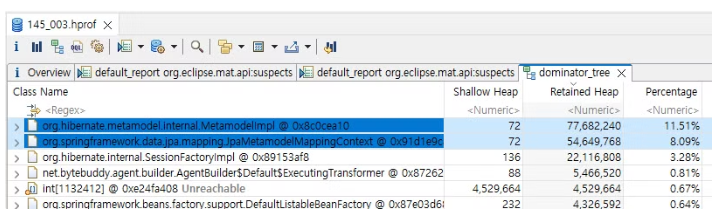
Dominator_tree의 상위 두 객체가 19%, 전체 힙중의 거의 130MB를 소모하는 것을 확인했다.
이 상위 두 객체는 org.hibernate.metamodel.internal.MetamodelImpl와, org.springframework.data.jpa.mapping.JpaMetamodelMappingContext이다.

이 두 객체는 각각 entityPersisterMap과 persistentEntities 맵을 포함하고 있으며, 이 맵들이 대부분의 메모리를 사용하고 있다.
entityPersisterMap은 Hibernate에서 엔티티를 관리하는 데 사용되는 맵으로, 많은 엔티티와 관련된 메타데이터를 포함하고 있을 수 있다. 이 맵의 크기가 큰 이유는 다음과 같을 수 있다:
- 엔티티 수: 애플리케이션에서 관리하는 엔티티의 수가 많으면, 그에 따라 entityPersisterMap의 크기도 증가한다.
- 엔티티 메타데이터: 각 엔티티에 대한 메타데이터가 크면, 맵의 크기도 증가한다.
persistentEntities 분석
persistentEntities는 Spring Data JPA에서 엔티티를 관리하는 데 사용되는 맵으로, 많은 엔티티와 관련된 메타데이터를 포함하고 있을 수 있다. 이 맵의 크기가 큰 이유는 다음과 같을 수 있다:
- 엔티티 수: 애플리케이션에서 관리하는 엔티티의 수가 많으면, 그에 따라 persistentEntities의 크기도 증가한다.
- 엔티티 메타데이터: 각 엔티티에 대한 메타데이터가 크면, 맵의 크기도 증가한다.
4. Histogram 분석
Histogram은 힙 덤프 파일 내의 객체들의 메모리 사용량을 클래스별로 보여준다. 이를 통해 메모리 누수를 일으키는 객체 클래스들을 식별할 수 있다.
- Histogram 열기:
- Histogram 탭을 열고, 각 클래스별 메모리 사용량을 확인한다.
- 메모리 사용량 분석:
- 메모리 사용량이 많은 클래스들을 중심으로 분석하여, 어떤 클래스의 객체들이 가장 많은 메모리를 차지하고 있는지 확인한다.
- 특정 클래스의 객체가 예상보다 많은 메모리를 차지하고 있다면, 해당 클래스가 메모리 누수의 원인일 수 있다.
이전에 이어, HashMap이 많은 데이터를 소모하는 이유를 찾아보자. (List Objects > With incoming references를 선택)
역시, 이전에 봤던 ‘persistentEntities’가 보인다.
다음과 같이 GC Roots를 통해 어떤 참조값을 가지는지 확인해보자.
unreachable 값들이 포함된 값이지만, 현재는 GC에 남아있는 소량의 Heap 메모리만 표기됨.
실제 Dominator tree의 세부 객체를 클릭하여 확인하면, 이것이 참조되는 위치(key)를 알 수 있다.
비슷하게, 다른 스냅샷의 경우 QueryPlanCashe에서 많은 메모리 누수가 발견되었다.
(유사한 블로그 포스팅을 참조한다. : https://velog.io/@recordsbeat/JPA-hibernate-Plan-Cache로-인한-OutOfMemory-해결)
동일한 쿼리가 반환하는 데이터의 양이 많을 경우, 메모리 사용량이 증가하는 원인은 다음과 같다.
- 결과 데이터의 메모리 사용량:
- 쿼리의 결과로 반환되는 데이터가 많으면, 그 데이터를 메모리에 저장하는 데 더 많은 공간이 필요하다.
- 예를 들어, 10개의 레코드를 반환하는 쿼리와 1000개의 레코드를 반환하는 쿼리는 동일한 쿼리 텍스트라도 반환되는 데이터의 양 때문에 메모리 사용량이 다르다.
- 결과 리스트의 크기:
- 반환된 데이터는 일반적으로 List와 같은 컬렉션에 저장된다. 이 컬렉션 자체도 메모리를 사용한다.
- 결과 데이터가 많을수록 리스트의 크기도 커지고, 그만큼 메모리 사용량이 증가한다.
상황 정리
- 동일한 쿼리를 사용하지만, 조회하는 데이터 양이 매우 많음.
- 힙 덤프 분석 결과 QueryPlanCache에서 많은 메모리 누수가 발생.
- 캐시된 쿼리 자체는 단순함.
문제의 핵심
QueryPlanCache에서 메모리 누수가 발생하는 이유는 쿼리 자체의 복잡성보다는 쿼리 결과 데이터의 양이 매우 많기 때문이다. 결과 데이터가 많을 경우, 관련된 객체들이 많이 생성되고 이들이 메모리에 남아 있는 경우가 많다.
왜 많은 힙을 차지하는가?
1. QueryPlanCache의 내부 동작
히베르네이트의 QueryPlanCache는 쿼리 실행 계획을 캐시하여 성능을 향상시킨다. 하지만 이 과정에서 캐시에 저장된 쿼리 실행 계획이 쿼리 결과와 관련된 많은 객체들을 간접적으로 참조하게 된다.
2. 메모리 사용 증가의 원인
- 쿼리 플랜의 복잡성: 쿼리 자체는 단순하지만, 결과 데이터가 많으면 결과를 매핑하는 데 필요한 메타데이터와 객체들이 많아진다.
- 매핑 객체: 수백만 개의 데이터를 매핑하려면 많은 매핑 객체와 컬렉션이 필요하다. 이러한 객체들이 캐시와 연관되면 메모리 사용량이 증가할 수 있다.
- 간접 참조: 쿼리 결과를 처리하는 과정에서 생성된 객체들이 캐시의 간접 참조로 남아 메모리에 계속 존재하게 된다.
예시와 설명 : 동일한 쿼리 텍스트
sql코드 복사
SELECT metric_id, start_time_unix_nano, time_unix_nano, value, attributes->>'jvm.memory.pool.name'
FROM tbl_apm_sum_jvm_memory_limit
WHERE created_at BETWEEN to_timestamp(?2 / 1000000000) AND to_timestamp(?3 / 1000000000)
AND agent_id = ?1
AND attributes->>'jvm.memory.type'='non_heap';
캐시와 메모리 사용의 관계
- 동일한 쿼리 텍스트를 사용하면 캐시된 쿼리 플랜의 수는 적을 수 있지만, 쿼리 결과 데이터가 많으면 이를 매핑하는 객체들이 많아진다.
- 이러한 매핑 객체들은 히베르네이트의 내부 구조에서 참조되어 메모리에 남아 있을 수 있다.
메모리 누수의 구체적 원인
1. 많은 매핑 객체
쿼리 결과가 많을 경우, 결과 데이터를 매핑하는 객체들이 많이 생성된다. 이러한 객체들이 힙 메모리에 많이 차지하게 된다.
2. 캐시된 객체들
캐시에 저장된 쿼리 실행 계획이 간접적으로 많은 결과 객체들을 참조하게 되어, 가비지 컬렉터가 이를 수집하지 못하는 상황이 발생할 수 있다.
해결 방안
- 캐시 크기 제한
- 히베르네이트 설정에서 캐시 크기를 제한하여 메모리 사용을 관리한다.
properties코드 복사 hibernate.query.plan_cache_max_size=100 - 캐시 만료 정책 적용
- 오래된 캐시 항목을 자동으로 제거하는 정책을 설정하여 캐시 크기를 관리한다.
- 예를 들어, 일정 시간 이상 사용되지 않은 캐시 항목을 제거하는 설정을 추가한다.
실행 결과가 메모리를 많이 차지할 수 있는 이유:- 결과 데이터 크기:
- 쿼리 결과로 반환된 데이터의 양이 매우 많다면, 이를 저장하기 위해 많은 메모리가 필요하다.
- 예를 들어, 수십만 건의 레코드가 반환되면, 이를 리스트나 컬렉션 형태로 메모리에 저장하기 위해 큰 용량이 필요하다.
- 엔티티 변환:
- JPA에서는 쿼리 결과를 엔티티 객체로 변환하여 관리한다. 이 과정에서 각 엔티티 객체가 메모리를 사용하게 된다.
- 특히, 네이티브 쿼리의 경우 결과를 엔티티로 매핑하는 과정에서 추가적인 메모리 오버헤드가 발생할 수 있다.
- 캐싱 메커니즘:
- 쿼리 결과가 캐시되면, 동일한 쿼리에 대해 반복적으로 데이터베이스 접근을 줄이기 위해 결과를 메모리에 저장하게 된다.
- 이를 통해 응답 시간을 줄일 수 있지만, 메모리 사용량이 증가할 수 있다
분석 2 : (24.06.19)
현재 대기중인 Heap의 대다수를 차지하는(50%) 상위 3개의 탭이다.

1. org.hibernate.metamodel.internal.MetamodelImpl
설명: MetamodelImpl 클래스는 Hibernate의 메타모델 구현 클래스이다. 이 클래스는 JPA 메타모델을 나타내며, 엔티티 클래스, 매핑 정보, 엔티티 관계 등을 포함하고 있다. 많은 엔티티와 복잡한 매핑이 있는 경우 이 클래스의 인스턴스가 많은 메모리를 차지할 수 있다.
주요 역할:
- JPA 엔티티 메타모델을 관리한다.
- 엔티티의 속성, 관계, 매핑 정보를 저장한다.
- 쿼리 생성 및 실행 시 메타데이터를 제공한다.
이 중 entityPersisterMap (ConcurrentHashMap)이 다수를 차지.
엔티티 퍼시스터(Entity Persister)를 관리하는 역할. (엔티티 퍼시스터는 엔티티의 상태를 데이터베이스와 동기화하는 데 사용되는 객체)
2. org.springframework.data.jpa.mapping.JpaMetamodelMappingContext
설명: JpaMetamodelMappingContext 클래스는 Spring Data JPA에서 사용되는 클래스이다. 이 클래스는 JPA 메타모델 정보를 Spring Data JPA 리포지토리와 매핑하기 위해 사용된다. 메타모델을 기반으로 리포지토리에서 사용할 수 있는 쿼리 메서드 등을 설정한다.
주요 역할:
- JPA 메타모델 정보를 Spring Data JPA 리포지토리에 매핑한다.
- 엔티티와 리포지토리 간의 관계를 관리한다.
- 쿼리 메서드와 매핑 정보를 설정한다.
이 중 다수를 차지하는 persistentEntities는 Spring Data JPA에서 사용하는 메타모델 매핑 컨텍스트로, 엔티티와 관련된 메타데이터를 저장하는 맵이다. 이 맵은 엔티티 클래스와 해당 메타데이터 간의 매핑을 관리한다.
3. org.hibernate.internal.SessionFactoryImpl
설명: SessionFactoryImpl 클래스는 Hibernate의 세션 팩토리 구현 클래스이다. 세션 팩토리는 Hibernate에서 세션을 생성하고 관리하는 중심 역할을 한다. 애플리케이션에서 데이터베이스와의 모든 상호작용은 세션 팩토리를 통해 이루어진다.
주요 역할:
- Hibernate 세션을 생성하고 관리한다.
- 데이터베이스 연결을 관리한다.
- 트랜잭션 관리, 캐싱, 엔티티 관리 등의 기능을 제공한다.