[ElasticSearch] 3. 벌크 데이터와 매핑, 데이터 타입과 문자열 처리
[ES]벌크 데이터와 매핑, 데이터 타입과 문자열 처리
벌크 데이터와 매핑 과정
벌크 데이터
벌크 데이터는 여러 개의 데이터 레코드가 모여 있는 것이다.
일반적으로 단일 작업으로 한 번에 처리될 수 있도록 모여있는 데이터 묶음으로, Elasticsearch에서는 REST API 호출 회수를 줄이고, 한번에여러 개의 인덱싱, 수정, 삭제 작업을 요청하기 위해 사용한다.
단, bulk API는 읽기 작업을 지원하지 않는다.
//해당 형태는 Json처럼 보이지만, NDJSON 형태이니 유의할 것.
POST /_bulk
{ "index" : { "_index" : "index1", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "index1", "_id" : "2" } }
{ "create" : { "_index" : "index1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "index1"} }
{ "doc" : {"field2" : "value2"} }현업에서는 해당 벌크 데이터를 쿼리보다는 file 형태로 사용한다.
매핑(Mapping)
데이터를 저장할 때, MySQL에서 스키마를 정의하듯 엘라스틱 서치 역시도 데이터를 저장할 규격이 필요할 것이다.
물론 Json 규격을 따라 엘라스틱 서치가 이를 자동으로 자료형으로 매핑해주지만, 모든 숫자가 long으로 저장된다면 그다지 효율적이지는 않을 것이다.
mapping을 통해 이를 확인할 수 있다. GET index2/_mapping 을 통해 index2의 매핑 정보를 확인해보자.

이처럼 자동으로 프로퍼티에 따라 값이 매핑되어 있는 것을 확인할 수 있다.
명시적 매핑 & 인덱스 이동
Elasticsearch는 이미 생성된 인덱스의 매핑을 변경하는 것이 제한적이기에, 매핑을 수정하려면 일반적으로 새로운 인덱스를 생성하고 데이터를 재색인해야 한다.
그러나 명시적 매핑을 사용하여 새 인덱스를 정의하고 데이터를 복사할 수 있다. 과정은 다음과 같다.
- 새로운 매핑을 포함하는 새로운 인덱스 생성.
- 기존 인덱스에서 새로운 인덱스로 데이터 재색인.
- 기존 인덱스 삭제.
- 새로운 인덱스 이름을 기존 인덱스 이름으로 변경(선택적).
예를 들어, index2의 name 필드에 analyzer를 추가하고 싶다면:
- 새로운 인덱스 생성:
PUT /index2_new
{
"mappings": {
"properties": {
"age": {
"type": "long"
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"gender": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}- 데이터 재색인:
POST /_reindex
{
"source": {
"index": "index2"
},
"dest": {
"index": "index2_new"
}
}- 기존 인덱스 삭제:
DELETE /index2새로운 인덱스 이름 변경(선택적):
POST /_aliases
{
"actions": [
{
"add": {
"index": "index2_new",
"alias": "index2"
}
}
]
}데이터 타입과 문자열 처리(Keyword, text)
데이터 타입
- Core Data Types
text: 텍스트 데이터로, 검색을 위해 전체 텍스트 분석됨.keyword: 텍스트 데이터로, 정확한 값 저장에 사용됨.long: 64비트 정수.integer: 32비트 정수.short: 16비트 정수.byte: 8비트 정수.double: 배정밀도 64비트 IEEE 754 부동 소수점.float: 단정밀도 32비트 IEEE 754 부동 소수점.date: 날짜와 시간, 기본적으로는strict_date_optional_time||epoch_millis형식이다.boolean: 참/거짓 값.
- Complex Data Types
object: JSON 객체.nested: 중첩된 JSON 객체.
- Geo Data Types
geo_point: 위도와 경도로 구성된 지리적 위치.geo_shape: 다양한 지리적 형상(예: 다각형, 원)을 나타내는 데이터.
- Specialized Data Types
ip: IPv4와 IPv6 주소.completion: 자동 완성 기능에 사용되는 데이터 타입.token_count: 텍스트 필드의 토큰 수를 카운트함.
- Array Data Type
- 배열: 동일한 타입의 여러 값. 예를 들어,
string배열이나integer배열.
- 배열: 동일한 타입의 여러 값. 예를 들어,
- Range Data Types
integer_range,float_range,long_range,double_range,date_range: 범위를 나타내는 데이터 타입.
문자열 처리
String 문자열이 5버전 이후 text + keyword로 분리되었다.
각자의 특징을 알아보자.
1. 텍스트 분리
text
- 특징:
- 전체 텍스트 분석을 위해 설계되었다.
- 분석기(analyzer)에 의해 텍스트가 토큰화되어 역색인된다.
- 검색 시 입력 텍스트도 같은 분석기를 통과하게 되어 토큰화된 검색어와 일치하는 문서를 찾게 한다.
- 사용 사례:
- 검색에 최적화된 필드로, 검색 쿼리에서 사용될 때 유용하다. 예를 들어, 긴 문장이나 문단의 내용을 검색할 때 사용됨.
- 예: 블로그 게시물의 본문, 상품 설명 등.
//예시로 text 값을 넣어보자. 공백 값을 기준으로 분리되는 것을 확인할 수 있을 것이다.
POST _analyze
{
"analyzer": "standard",
"text": "hello, welcome to my tistory blog. I want to get more Intellegence and Java skill about programming."
}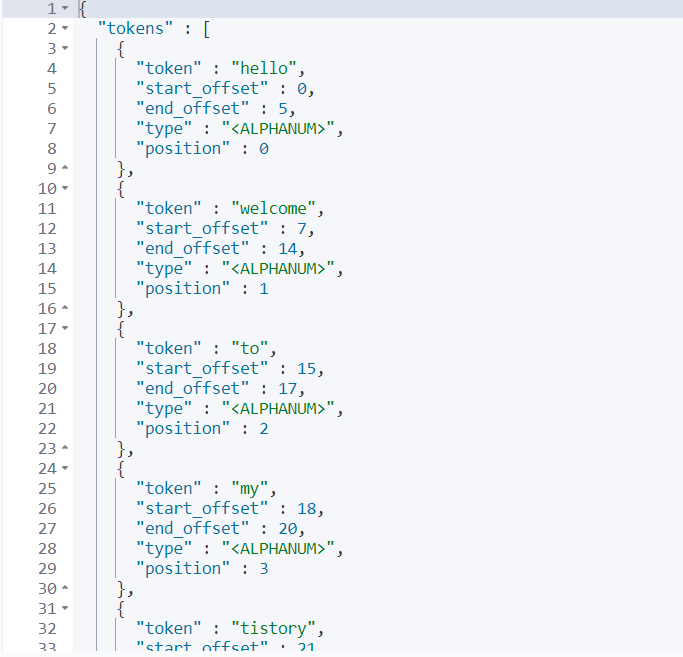
이렇게 분리된 토큰들이 인덱싱되는 과정을 역인덱싱이라고 한다. 그리고 역인덱스에 저장된 토큰들을 용어(term)라고 정의한다.
//직접 텍스트 타입을 매핑해보자.
PUT text_index
{
"mappings": {
"properties": {
"contents": { "type": "text" }
}
}
}
//content를 text 타입으로 매핑하였다.
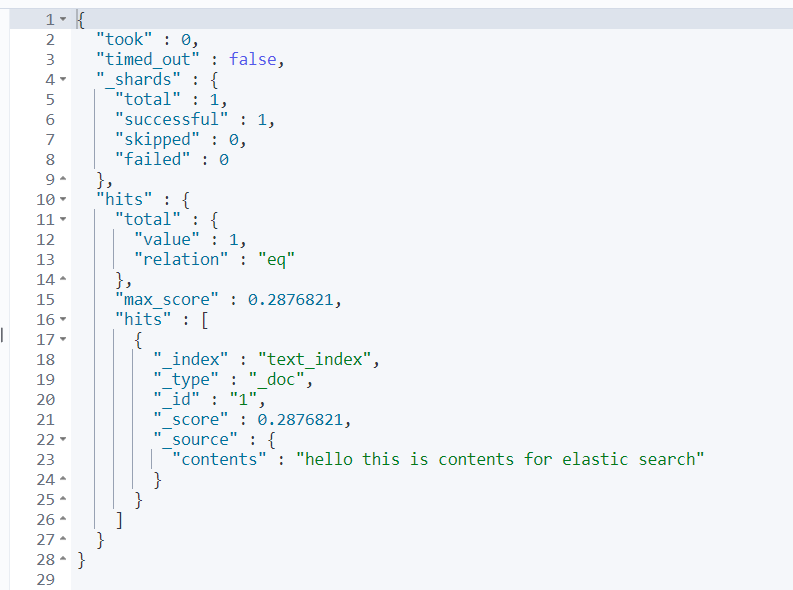
//이후 맞춰서 도큐먼트를 하나 넣어보자.
PUT text_index/_doc/1
{
"contents" : "hello this is contents for elastic search"
}
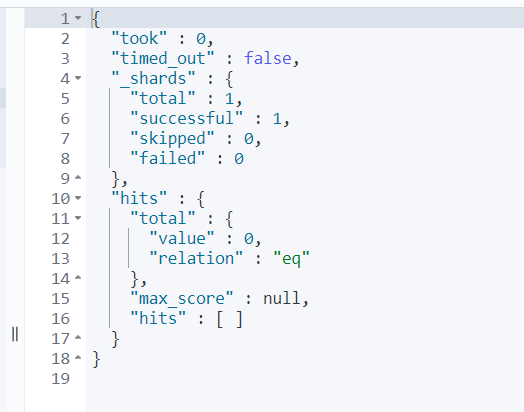
//매핑한 값을 확인해보자. 일반적으로 GET 방식과 query파라미터를 사용해 확인한다.
//hello의 경우 value 1, hello1의 경우 value 0임을 확인할 수 있다.
GET text_index/_search
{
"query": {
"match": {
"contents": "hello"
}
}
}
2. 키워드 분리
keyword
- 특징:
- 정확한 값 저장을 위해 설계되었다.
- 분석되지 않고 원본 그대로 저장되므로, 텍스트 분석기를 통과하지 않는다.
- 필터링, 정렬, 집계(aggregations)에 적합하다.
ignore_above옵션을 통해 특정 길이 이상의 문자열은 인덱싱에서 제외할 수 있다.
- 사용 사례:
- 정확한 값을 필요로 하는 필드에 사용됨. 예를 들어, ENUM과 같은 정해진 값 또는 ID, 이메일 주소, 호스트 이름, 상태 코드, 태그 등. 반대로 전문을 검색할 경우, 명확하게 값이 나오는 것을 확인할 수 있다.
//이번에는 키워드 단위로 매핑해보자.
PUT keyword_index
{
"mappings": {
"properties": {
"contents": { "type": "keyword" }
}
}
}
//삽입
PUT keyword_index/_doc/1
{
"contents" : "hello how are you? keyword search is good"
}
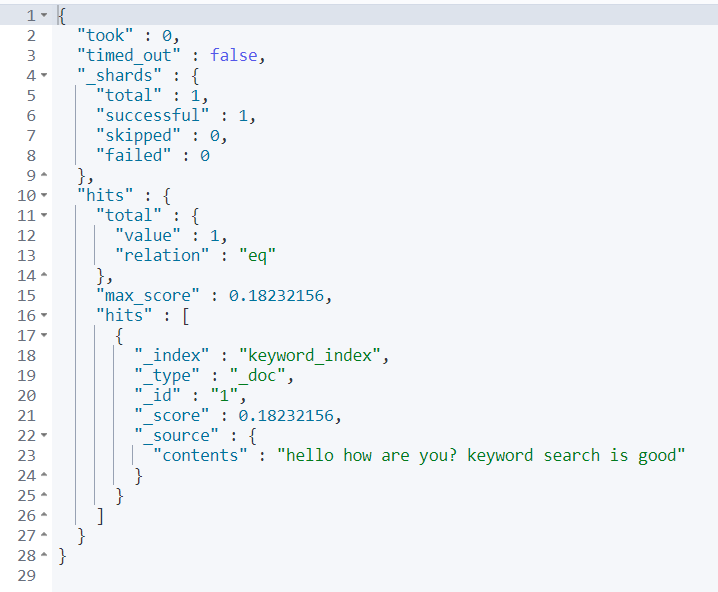
//이후 특정 키워드를 검색해보자
GET keyword_index/_search
{
"query": {
"match": {
"contents": "good"
}
}
}
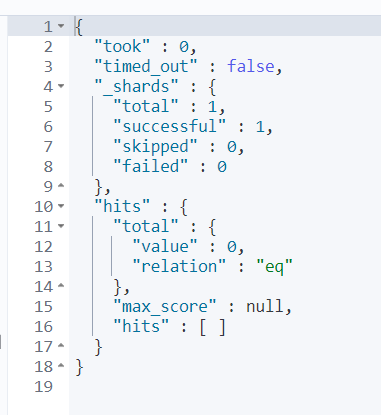
이전의 text와 달리, 검색 결과가 나오지 않는다. 이는 keyword의 특성에 따라 정확히 입력해야 도큐먼트를 찾을 수 있기 때문이다.
반대로 전문을 검색할 경우, 명확하게 값이 나오는 것을 확인할 수 있다.