개요
기존 프로젝트에서 우리는 오타를 보정하기 위해 검색어와 가장 유사한 검색어들을 차등적으로 리스트의 형태로 제공했다.
이 과정에서 Ngram과 Fuzzy의 분석 결과를 요청하고, 이를 다시 합산하여 가장 스코어가 높은 순서대로 유사하다는 결론을 내렸다.
//통합 제목 검색 : 제목 일치 or (Fuzzy + ngram)
@GetMapping("/title/aggregate-search")
public List<ResponseRestaurantDto> searchTitleComprehensive(@RequestParam("title") String title,
@RequestParam("maxResults") int maxResults,
@RequestParam("fuzziness") int fuzziness,
@RequestParam("fuzzyPrimary") boolean fuzzyPrimary)
{
try {
List<ResponseRestaurantDto> responseRestaurantDtoList = restaurantServiceBasic.searchExactRestaurantName(title, maxResults);
if (responseRestaurantDtoList.size() != 0) {
return responseRestaurantDtoList;
} //1. 일치 제목 검색이 있다면 이를 리스트에 추가 후 리턴
return restaurantTitleService.searchFuzzyAndNgram(title, maxResults, fuzziness, fuzzyPrimary); //2. 결과가 없다면 두 검색 진행 후 유사도별로 정렬
} catch (Exception e) {
log.error("[ERR LOG] {}", e.getMessage());
throw new CommonException(ExceptionType.RESTAURANT_AGGREGATE_TITLE_SEARCH_FAIL);
}
}
스코어를 합산한 네이밍 결과값을 토대로, 최종적인 결과를 가져오는 과정에서 should 구문을 활용하여 네트워크 오버헤드를 최대한 줄여보는 로직을 작성하였다.
당연히 여러 번의 동일 API 요청보다는, 한 번에 모든 요청을 보내고 이를 후처리하는 과정이 더욱 효율적일 것이다.
이를 모의로 전송하고, 결과를 받아오기까지 걸리는 시간을 측정해보았다.
코드
API 반복 요청을 통한 코드
public List<ResponseRestaurantDto> searchFuzzyAndNgramTest(String title, int maxResults, int fuzziness, boolean fuzzyPrimary) {
//maxResult가 적으면 적은 List셋에 고만고만한 값만 나와 유의미한 검색 결과가 나오지 않음. 가장 큰 이슈였다.
int searchCount = Math.max(maxResults, 40); //최소 40개로 검색 결과를 보장 : 10개 정도라면 비슷한 값만 나올 수도 있음.
int fuzzyWeight, ngramWeight; //가중치 여부 : fuzzyPrimary에 따라 다름
if(fuzzyPrimary) { //가중치 부여
fuzzyWeight = 7;
ngramWeight = 3;
} else {
fuzzyWeight = 3;
ngramWeight = 7;
}
List<ResponseRestaurantDto> fuzzyList = searchTitleUseFuzzyDto(title, searchCount, fuzziness);
List<ResponseRestaurantDto> ngramList = searchTitleUseNgramDto(title, searchCount);
//두 리스트를 합치고 스코어가 있다면 가중
HashMap<String, Float> alladdHashMap = new HashMap<>();
//1. fuzzy 삽입
for (ResponseRestaurantDto dto : fuzzyList) {
alladdHashMap.put(dto.getRestaurantName(), (dto.getScore() * fuzzyWeight));
}
//2. ngram 삽입, fuzzy와 동일한 지명이 있다면 스코어 가중
for (ResponseRestaurantDto dto : ngramList) {
if(alladdHashMap.containsKey(dto.getRestaurantName())) {
alladdHashMap.put(dto.getRestaurantName(),
alladdHashMap.get(dto.getRestaurantName()) + (dto.getScore() * ngramWeight));
} else alladdHashMap.put(dto.getRestaurantName(), (dto.getScore() * ngramWeight));
}
//스트림을 통해 해시맵 내림차순 정렬 후 리스트화
List<String> nameList = alladdHashMap.entrySet()
.stream() //HashMap을 스트림으로 변환
.sorted(Map.Entry.<String, Float>comparingByValue().reversed()) //value를 기준으로 내림차순 정렬
.limit(maxResults)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
List<ResponseRestaurantDto> queryResult = new ArrayList<>();
// 각 제목에 대한 개별 검색
for (String name : nameList) {
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.termQuery("food_name.keyword", name))
.withPageable(PageRequest.of(0, maxResults))
.build();
// 각 검색 결과를 저장
queryResult.addAll(toolsForRestauantService.getListBySearchHits(elasticsearchRestTemplate.search(searchQuery, Restaurant.class)));
}
return queryResult;
}
Bool - Should를 사용해 모든 요청값을 가져오고, 이후 서버에서 후처리하는 로직
public List<ResponseRestaurantDto> searchFuzzyAndNgram(String title, int maxResults, int fuzziness, boolean fuzzyPrimary) {
//maxResult가 적으면 적은 List셋에 고만고만한 값만 나와 유의미한 검색 결과가 나오지 않음. 가장 큰 이슈였다.
int searchCount = Math.max(maxResults, 40); //최소 40개로 검색 결과를 보장 : 10개 정도라면 비슷한 값만 나올 수도 있음.
int fuzzyWeight, ngramWeight; //가중치 여부 : fuzzyPrimary에 따라 다름
if(fuzzyPrimary) { //가중치 부여
fuzzyWeight = 7;
ngramWeight = 3;
} else {
fuzzyWeight = 3;
ngramWeight = 7;
}
List<ResponseRestaurantDto> fuzzyList = searchTitleUseFuzzyDto(title, searchCount, fuzziness);
List<ResponseRestaurantDto> ngramList = searchTitleUseNgramDto(title, searchCount);
//두 리스트를 합치고 스코어가 있다면 가중
HashMap<String, Float> alladdHashMap = new HashMap<>();
//1. fuzzy 삽입
for (ResponseRestaurantDto dto : fuzzyList) {
alladdHashMap.put(dto.getRestaurantName(), (dto.getScore() * fuzzyWeight));
}
//2. ngram 삽입, fuzzy와 동일한 지명이 있다면 스코어 가중
for (ResponseRestaurantDto dto : ngramList) {
if(alladdHashMap.containsKey(dto.getRestaurantName())) {
alladdHashMap.put(dto.getRestaurantName(),
alladdHashMap.get(dto.getRestaurantName()) + (dto.getScore() * ngramWeight));
} else alladdHashMap.put(dto.getRestaurantName(), (dto.getScore() * ngramWeight));
}
//스트림을 통해 해시맵 내림차순 정렬 후 리스트화
List<String> nameList = alladdHashMap.entrySet()
.stream() //HashMap을 스트림으로 변환
.sorted(Map.Entry.<String, Float>comparingByValue().reversed()) //value를 기준으로 내림차순 정렬
.limit(maxResults)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
//추려진 값들을 should를 사용하여 동시적으로 조회 (리스트 내부에 있는 제목의 검색 결과는 리턴됨)
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
for (String name : nameList) {
boolQueryBuilder.should(QueryBuilders.termQuery("food_name.keyword", name));
}
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withPageable(PageRequest.of(0, maxResults)) // maxResults만큼 결과
.build();
List<ResponseRestaurantDto> queryResult = toolsForRestauantService.getListBySearchHits(elasticsearchRestTemplate.search(searchQuery, Restaurant.class));
//최종 합산 결과 저장, 이전 스코어 순서대로 재정렬
List<ResponseRestaurantDto> results = new ArrayList<>();
for (String name : nameList) {
queryResult.stream() // queryResult 리스트를 스트림으로 변환
.filter(dto -> dto.getRestaurantName().equals(name)) // 현재 이름과 일치하는 ResponseRestaurantDto 객체 필터링
.findFirst() // 필터링된 스트림에서 첫 번째 요소 찾기 (일치하는 첫 번째 객체)
.ifPresent(results::add); // 일치하는 객체가 존재하면 sortedResults 리스트에 추가
}
return results;
}
실제 요청 시간 테스트
Bool - should 개선 로직(count = 10)

기존 API 반복 요청 로직(count = 10)

10회의 경우 최대 4배 정도의 시간 차이가 나는 것을 확인할 수 있다.
물론 이 값은 요청 회수가 커질수록 유의미하게 차이난다.
우리 서비스에서 최대한 제공할 수 있는 count인 100의 경우를 살펴보자.
100개 요청의 경우

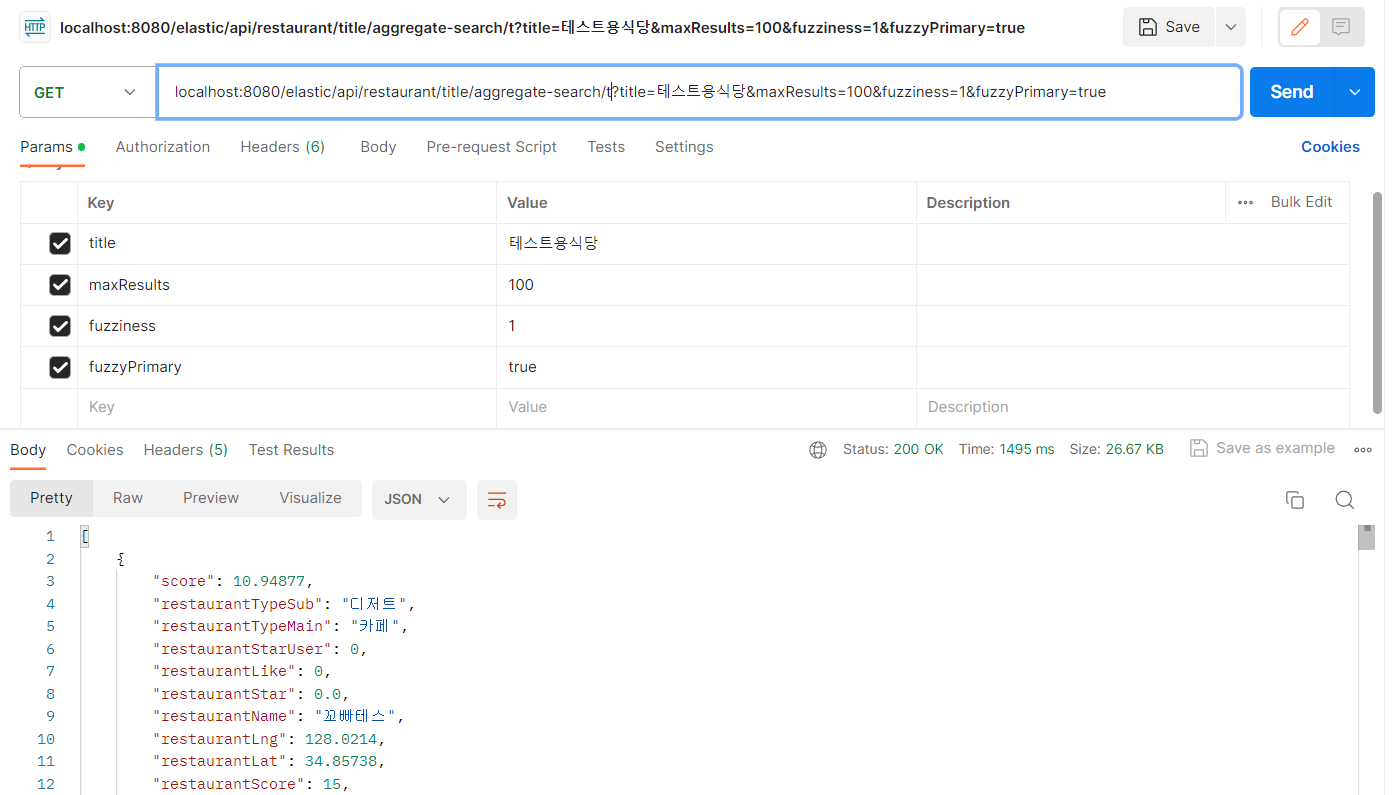
이 정도면 사실상 API 역할을 할 수 없는 요청 속도이다.
한번의 요청으로 모든 결과값을 얻고 이를 서버 단에서 비즈니스 로직으로 다시 분류하는 과정을 거쳐, 최대 9~10배의 시간적 효율을 얻을 수 있었다.
'프로젝트 > 여행지 오픈 API' 카테고리의 다른 글
| [LogBack]API 요청 로그 수집하기 (0) | 2023.11.22 |
|---|---|
| [Kibana] Kibana 데이터시각화 구현 (0) | 2023.11.21 |
| [ElasticSearch] 최종 인덱스, 중복 문제와 오탈자 검색의 고민 (1) | 2023.11.13 |
| [정리]analyzer를 사용한 수집 정보의 유사성 계산 (0) | 2023.11.09 |
| ES 서버 Nginx 설정(xpack 보안 설정) (2) | 2023.11.08 |



