역인덱싱
엘라스틱서치의 역인덱싱(inverted indexing)은 문서가 포함하고 있는 각 단어의 색인을 만드는 과정을 말한다.
각 단어에 대한 문서의 참조를 역순으로 저장하는데, 이렇게 하면 검색 엔진이 단어를 빠르게 찾고 해당 단어가 포함된 모든 문서를 즉각적으로 확인할 수 있다.
역인덱싱의 시간 복잡도
1. 색인 생성: 각 문서에 대해 단어를 추출하고 색인을 만드는 데 O(N * M)의 시간이 걸린다. 여기서 N은 문서의 수, M은 문서당 평균 단어 수다.
2. 검색 연산: 색인이 생성되고 나면, 특정 단어의 검색은 매우 빠르다. 색인에서 직접 해당 단어에 접근하여 연관된 문서들을 찾을 수 있으므로, 이론적으로 O(1)에 가까운 시간 복잡도를 갖는다. 하지만 실제로는 검색어에 대해 매칭되는 문서들의 리스트를 반환하므로, 최종 시간 복잡도는 반환되는 문서의 수에 영향을 받는다.
MySQL의 Like 연산의 경우
MySQL의 LIKE 연산은 와일드카드 검색을 통해 특정 패턴이 포함된 튜플을 찾는데, 인덱싱을 활용하지 않는 경우(와일드카드가 문자열 앞에 위치하는 경우 등) 전체 테이블 스캔을 요구하므로 성능 저하가 일어날 수 있다.
만약 쿼리가 와일드카드 '%'를 접두사로 사용하지 않는다면, 인덱스를 활용할 수 있어 성능이 나아질 수 있다. 하지만 여전히 범위 스캔(range scan)이 발생할 수 있다.
만약 '%'가 접두사로 사용된다면, MySQL은 전체 테이블 스캔을 수행해야 하므로 시간 복잡도는 O(N)이 된다. 여기서 N은 테이블의 행 수다.
요약하자면, 엘라스틱서치는 대량의 데이터에서 텍스트를 빠르게 검색할 수 있도록 설계된 반면, MySQL의 LIKE 연산은 인덱스의 활용 여부에 따라 성능이 크게 달라질 수 있다.
테스트
1. MySQL Like의 경우
https://jaehoney.tistory.com/138
MySQL - 쿼리 성능(실행 시간, CPU 사용량 등) 확인하는 방법 [Profiling]
MySQL Profiling MySQL에서 실행한 쿼리들이 각 수행 시간이 얼마가 걸렸는지 확인할 수 있는 기능으로 쿼리 프로파일링(Query Profiling)을 제공합니다. profiling 설정을 활성화하면 앞으로 실행되는 모든
jaehoney.tistory.com
쿼리 성능 측정은 다음 포스팅을 참고하였다.


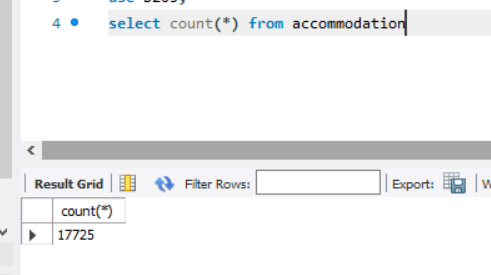
17725개의 튜플 like 검색 시 대략 0.013~ 0.014초의 시간이 걸리는 것을 확인할 수 있었다.
2. ElasticSearch의 경우
(사진 손실)
ElasticSearch의 경우 단순 keyword 쿼리로 검색 시 0.002초의 시간이 걸림을 확인할 수 있었다.
물론 MySQL 역시 select 구문을 사용할 경우 0.001초~ 0.002초의 유의미한 결과가 있지만, Like문을 대체하기에 ES가 더욱 유용하게 사용됨을 확인할 수 있었다.
물론 MySQL의 경우 해당 단어를 '명확하게' 일치하는 값을 찾아온다는 점과, ES의 경우 match 등을 통해 토큰화된 용어를 탐색한다는 점이 다르기는 하겠지만, 대부분의 검색 과정에서 Elasticsearch가 유사 내용 검색 및 결과에 도움이 될 것이다.
'프로젝트 > 여행지 오픈 API' 카테고리의 다른 글
| ES 서버 Nginx 설정(xpack 보안 설정) (2) | 2023.11.08 |
|---|---|
| [Elasticsearch] 여행지 정보 키워드 추출, 집계 (0) | 2023.11.07 |
| [ElasticSearch] 집계함수 정의와 적용 (0) | 2023.11.06 |
| [ElasticSearch] Script 쿼리와 Must 쿼리 (0) | 2023.11.03 |
| [ElasticSearch] NativeQuery (0) | 2023.11.03 |


