구축 환경 Diagram과 Flow


설치 환경 및 설치 버전
- CentOS 7 / windows 11(Scouter window Client)
- Java 1.8
<Pinpoint>
Pinpoint v2.3.3
Release v2.3.3 · pinpoint-apm/pinpoint
Security Patch Release Fix Log4j2 Security Vulnerabilities CVE-2021-45105, CVE-2021-45046 Agent : log4j 2.12.3 Server module : log4j 2.17.0 Release Notes [#8510] Backport: Bump Log4j 2.17.0 b...
github.com
Hbase 1.4.6
Flink 1.6.2
1. Hbase 설치 및 실행
설치
Pinpoint를 사용하기에 앞서, 해당 서비스가 주로 데이터를 저장하는 Hbase를 설치받아야 한다.
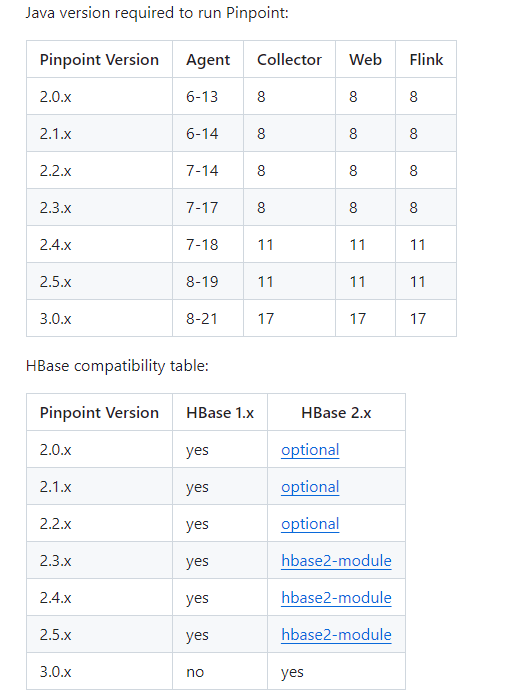
버전에 맞는 hbase를 설치하자.
https://archive.apache.org/dist/hbase/1.4.6/
Index of /dist/hbase/1.4.6
archive.apache.org
sudo tar -xvf hbase-1.4.6-bin.tar.gz
환경설정
hbase의 conf 파일 하위의 hbase-site.xml를 수정해주어야 한다.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///opt/hbase-1.4.6/data/hbase_data</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase-1.4.6/data/zookeeper_data</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property></configuration>
여기서 rootdir과 zookeeper dataDir은 내가 임의로 만든 경로이다. 이 경로에 데이터가 저장되게 된다.
이제 bin 폴더 내부의 start-hbase와 stop-hbase를 통해 hbase DB를 제어할 수 있다.
실행과 스키마 생성 스크립트
여기서 Pinpoint가 주로 사용하는 Table들을 스크립트로 저장해놓은 파일이 존재하니, 이걸 받아 내 hbase table에 저장하자.
https://github.com/pinpoint-apm/pinpoint/blob/2.3.x/hbase/scripts/hbase-create.hbase
hbase 설치 폴더 - bin 이동. 이후 start-hbase.sh 실행.
이후, pinpoint에서 제공하는 table 설치 스크립트(다운받은 뒤 bin 폴더 내부로 옮겼다.)를 시작하자.
기본적으로 hbase-create.hbase일 것이다.
#hbase-create.hbase는 받은 파일의 이름.
./hbase shell hbase-create.hbase
적용이 완료되었다면 './hbase shell'을 통해 shell을 열고, list를 통해 현재 존재하는 테이블을 확인해보자.

다음과 같이 정상적으로 테이블이 추가되었다면 다음으로 넘어가도 좋다.
2. pinpoint web, collector
실행 시 명령어
web과 collector는 git에서 받은 jar 파일을 그대로 실행하기만 하면 된다. (일반적으로, 별다른 설정 없어도 동작한다.)
다만, 실행시 몇 가지 명령어를 적용해야 한다.
매 실행시마다 번거로우니 아래처럼 script의 형태로 작성해도 되고, 명령어로 직접 타이핑해도 문제는 없다.
echo "Pinpoint Web Load.."
# nohup /opt/java/openlogic-openjdk-8u392-b08-linux-x64/bin/java -jar -Dpinpoint.zookeeper.address=localhost /opt/pinpoint/pinpoint-web-boot-2.3.3.jar --server.port=8180 &
# 간혹 경로를 찾을 수 없는 경우가 있는데, 이 경우 export하거나 위처럼 전체 자바 경로를 잡아주어도 된다.
nohup java -jar -Dpinpoint.zookeeper.address=localhost /opt/pinpoint/pinpoint-web-boot-2.3.3.jar --server.port=8180 &
sleep 1
echo "Pinpoint Collector Load.."
nohup java -jar -Dpinpoint.zookeeper.address=localhost /opt/pinpoint/pinpoint-collector-boot-2.3.3.jar --server.port=8181 &
sleep 1
echo "Well Done"
기본적으로 nohup을 통해 백그라운드로 실행하며, 실행 명령어의 옵션은 다음과 같다.
-Dpinpoint.zookeeper.address=localhost : 내장 Zookeeper의 경로(hbase 내장이기에 localhost)
opt/pinpoint/pinpoint-collector-boot-2.3.3.jar : 실행하는 파일의 전체 경로
--server.port=8181 : 생성할 서버의 포트
Collector - Agent 연결 포트
Agent 설정에서 변경할 수 있긴 하지만, 기본적으로 9991 ~ 9993 포트를 이용한다.
따라서 해당 포트를 열어주어야 Agent와의 정상적인 연동이 가능하다.
Agent Conf는 추후 후술한다.
3. pinpoint Agent 환경 설정
Web과 Collector를 설치하였다면 Agent를 측정하고자 하는 서버에 설치하자.
이후 환경 설정을 통해 Agent를 동작할 수 있다.
Agent root config
agent 폴더의 'pinpoint-root.config'에서 세부 설정을 진행할 수 있다.

다양한 옵션이 존재하지만, 기본적으로 무조건 설정해야 하는 것은 Collector 서버의 주소이다.
profiler.transport.grpc.collector.ip=192.168.56.1(예시 주소)
Tomcat config - catalina.sh (setenv.sh)
이전 Scouter의 경우와 같이, Pinpoint agent 역시도 데이터를 가져오고자 하는 Tomcat의 부팅 시 같이 실행되도록 할 수 있다. (독자적으로 jar로 실행하지 않아도 된다는 이야기이다.)
이를 위해 파싱을 원하는 Spring(tomcat) 내부의 tomcat/bin/catalina.sh에서 다음과 같은 설정을 진행하고, tomcat 부트 시 agent가 동작하게 할 수 있다.

# ----- Execute The Requested Command ----------------------------------------- 라인 이전에 작성하여야 하며, 자세한 내용은 다음과 같다.
#pinpoint agent Setting
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/opt/pinpoint/pinpoint-agent-2.3.3/pinpoint-bootstrap-2.3.3.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=Agent240124"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=TestTomcatServer240124"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.config=/opt/pinpoint/pinpoint-agent-2.3.3/pinpoint-root.config"
1. agent jar 파일의 경로
2. agentId
3. agentName
4. root-config 설정 파일을 참조
tomcat 재부팅 후, ' ps -ef | grep pinpoint.agent' 를 통해 실행 상태를 확인해보자.
4. Flink
agent로부터 수집된 데이터는 collector가 저장하고, 이를 Flink의 동시 스트림 로직으로 넘겨준다.
그리고 flink job을 통한 데이터 처리 단계를 거쳐 최종적으로 hbase에 저장된다.
따라서 데이터를 정상적으로 저장하고 읽기 위해서는 Flink와 Flink job을 설치하고 적용해야 한다.

Flink 설치 및 실행(1.6.3)
https://archive.apache.org/dist/flink/flink-1.6.3/
Index of /dist/flink/flink-1.6.3
archive.apache.org
본 메뉴얼에서는 'flink-1.6.3-bin-hadoop24-scala_2.11.tgz' 버전을 압축 해제하였다.
Flink를 실행하기 위해 flink/bin/start-cluster.sh 의 파일을 실행하면 된다.
반대로 멈추려면 stop-cluster.sh의 스크립트를 실행하면 된다.
이후 flink가 실행됨을 확인할 수 있다.
예외 케이스 : java.net.UnknownHostException
해당 에러가 뜨면서 flink의 실행이 실패되는 경우가 있는데, 이 경우 실행하는 host의 정보를 알 수 없기 때문이다.

해결 방법은 두 가지이나, 후자를 추천한다.
1. 시스템 DNS 설정 또는 /etc/hosts 파일에 name 추가.
시스템 설정 문서에 실행하는 hostname을 추가하면 된다.
하지만 이 방법의 경우 민감한 문서에 접근해야 하므로 후자의 방법을 추천한다.
2. Flink Conf 문서에 host 정보 추가(taskmanager.host)

다음과 같이 Conf에 host의 주소를 localhost로 설정할 경우 실행 시 자기 자신을 호스트로 인식하여 실행할 수 있다.
5. Flink Job
Flink(cluster)를 실행하였으면, 이 Flink가 수행할 job을 적용시켜야 한다.
Pinpoint Github에서 자체적으로 job file 역시 제공하니, 이를 적용시켜 실행하면 된다.
설치 및 내부 설정 파일 적용
https://github.com/pinpoint-apm/pinpoint/releases/tag/v2.3.3
Release v2.3.3 · pinpoint-apm/pinpoint
Security Patch Release Fix Log4j2 Security Vulnerabilities CVE-2021-45105, CVE-2021-45046 Agent : log4j 2.12.3 Server module : log4j 2.17.0 Release Notes [#8510] Backport: Bump Log4j 2.17.0 b...
github.com

해당 파일을 받도록 하자. 아래의 경우 hbase 2.x 버전을 위한 jar 파일이다.
flink job의 경우 jar 파일 내부의 설정을 제대로 하지 않으면 부트 시 계속하여 에러가 발생하는데(특히 LocalStreamEnviroment), 이 경우 github issue로 제출하면 친절하게 답장해주시니 이 방법을 이용해도 괜찮다.
단, 이전 이슈를 꼭 확인해보자. 비슷한 오류가 많다.
이해가 잘 되지 않는다면 공식 레퍼런스의 빌드 방법을 따라할 것.
https://pinpoint-apm.github.io/pinpoint/applicationinspector.html
How to use Application Inspector | Leading Open-Source APM
English | 한글 Application Inspector 1. Introduction Application inspector provides an aggregate view of all the agent’s resource data (cpu, memory, tps, datasource connection count, etc) registered under the same application name. A separate view is p
pinpoint-apm.github.io
내부 jar 파일의 properties를 수정해야 한다.

핵심적인 부분은 'flink.StreamExecutionEnvironment=server' 옵션을 추가하는 것이다.
기본은 =local로 설정되어 있다.
profiles 폴더 하위에 relase / local에 'pinpoint-flink.properties'가 각각 존재하는데, 둘 다 전부 변경해주도록 할 것.
그 외 pinpoint-collector.properties, pinpoint-web.properties 역시 필요할 경우(에러가 난다면) 수정해야 한다.
기본 세팅으로 돌아가는 것을 확인했지만, address가 존재하기에 에러가 난다면 특정 주소로 바꿔주는 것을 고려하자.
<pinpoint-collector.properties file>
pinpoint.zookeeper.address=192.168.56.1 # 예를 들면 이런 부분. 에러가 난다면 특정 주소로 바꿔보자.
collector.scatter.serverside-scan=v2
실행
flink가 실행중이라면, 다음 명령어로 다운받아 수정한 jar 파일을 nohup으로 실행하자.
sudo nohup 설치 경로/bin/flink run 파일경로/pinpoint-flink-job-2.3.3.jar -Dspring.profiles.active=release &
sudo nohup 설치 경로/bin/flink run 파일경로/pinpoint-flink-job-2.3.3.jar -Dspring.profiles.active=release &
중요한 것은 /flink run으로 파일을 실행하고, -Dspring.profiles.active=release 옵션을 지정해야 한다는 것이다.
Flink Web UI
flink web을 열기 위해서는 /conf/flink-conf.yaml에서 다음 부분을 주석 해제하고, port를 지정해주자.
여기서는 8082 포트를 설정하였다.

jobmanager.web.address: 0.0.0.0
# The port under which the web-based runtime monitor listens.
# A value of -1 deactivates the web server.
rest.port: 8082
정상적으로 설정 후 실행하였을경우, 다음처럼 Flink Web과, Running 중인 flink job 프로세스의 상태를 확인할 수 있다.


6. 관리 Script
이처럼 Pinpoint를 유지하기 위해서는
1. hbase 실행 - 2. Flink 및 flink job 실행 - 3. pinpoint web/collector 실행 과정을 거쳐야 한다.
이것이 상당히 번거로웠기에, 본 예시의 경우 자체적으로 관리 스크립트를 만들어 실행과 종료 과정을 간략화하였다.
이를 추가적으로 참조한다. 기본적으로 root 계정으로 관리하였기에, 에러가 발생한다면 조금 더 구체적이고 세부적인 내용을 다듬어야 한다.
1. start.sh
######parameter#######
HBASE_HOME="/opt/hbase-1.4.6/bin" #Hbase 설치 경로
HBASE_LOG="/opt/hbase-1.4.6/logs" #hbase 로그 경로
FLINK_HOME="/opt/flink-1.6.3/bin" #Flink 설치 경로
PINPOINT_HOME="/opt/pinpoint" #Pinpoint 설치 경로
PINPOINT_VERSION="2.3.3"
###parameter for log dir
### 로그 경로
CURRENT_TIME=$(TZ="Asia/Seoul" date +"%Y%m%d_%H%M")
FLINK_JOB_DIR="/opt/script/logs/flink_job"
PINPOINT_WEB_DIR="/opt/script/logs/pinpoint_web"
PINPOINT_COL_DIR="/opt/script/logs/pinpoint_col"
#타이머가 없을 경우 정상 부트 이전에 다음 로직 실행 가능성 있음
set_timer() {
REMAIN_TIME=${1}
WAIT_TIME=0
while [ ${WAIT_TIME} -lt ${REMAIN_TIME} ]; do
WAIT_TIME=$((WAIT_TIME + 2))
echo "[Timer]wait ... ${WAIT_TIME} / ${REMAIN_TIME} sec"
sleep 2 # 2초 대기
done
}
## 1. start hbase
echo "1. start hbase"
echo "1-1. Start hbase shell"
sudo ${HBASE_HOME}/start-hbase.sh
echo "Waiting for booting Hbase Server..."
set_timer "14"
## 2. start Flink
sleep 1
echo "2-1. Start Flink Cluster"
sudo ${FLINK_HOME}/start-cluster.sh
echo "Waiting for booting Flink Server..."
set_timer "10"
echo "2-2. Start pinpoint-flink-job"
sudo nohup ${FLINK_HOME}/flink run ${FLINK_HOME}/pinpoint-flink-job-2.3.3.jar -Dspring.profiles.active=release > "$FLINK_JOB_DIR/pinpoint_flink_job_${CURRENT_TIME}.log" 2>&1 &
set_timer "6"
## 3. start Pinpoint
echo "3-1. Pinpoint Web Load.."
sudo nohup java -jar -Dpinpoint.zookeeper.address=localhost ${PINPOINT_HOME}/pinpoint-web-boot-${PINPOINT_VERSION}.jar --server.port=8180 > "$PINPOINT_WEB_DIR/pinpoint_web_${CURRENT_TIME}.log" 2>&1 &
set_timer "2"
echo "3-2. Pinpoint Collector Load.."
sudo nohup java -jar -Dpinpoint.zookeeper.address=localhost ${PINPOINT_HOME}/pinpoint-collector-boot-${PINPOINT_VERSION}.jar --server.port=8181 > "$PINPOINT_COL_DIR/pinpoint_col_${CURRENT_TIME}.log" 2>&1 &
set_timer "2"
## 4. end
echo "4. Find Hbase Web UI Port"
#grep, tail로 마지막 줄 탐색 후 ,awk 사용.
LAST_PORT=$(grep "Jetty bound to port" $HBASE_LOG/*.log | tail -n 1 | awk '{print $NF}')
echo "Hbase Web UI Port(Last Jetty) : $LAST_PORT"
echo "Boot Well Done, now Time = ${CURRENT_TIME}"
2. close.sh
#Close service
######parameter#######
HBASE_HOME="/opt/hbase-1.4.6/bin"
FLINK_HOME="/opt/flink-1.6.3/bin"
# 관련된 모든 프로세스 종료
close_process() {
PROCESS_NAME=${@}
while true; do
PID=$(pgrep -f "$PROCESS_NAME")
if ! pgrep -f $PROCESS_NAME > /dev/null; then
echo "No more ${PROCESS_NAME} is running."
break
else
echo "close ${PID}, find more ${PROCESS_NAME}..."
sudo kill -9 $PID
sleep 2
fi
done
}
##1. pinpoint web, collector
echo "1. Close Pinpoint"
close_process "pinpoint"
##2. flink job, cluster
echo "2-1. Close Flink Job"
JOB_ID=$(timeout 10s $FLINK_HOME/flink list | grep " : " | awk '{print $4}')
if [ ! -z "$JOB_ID" ]; then
echo "Cancelling Flink job with ID: $JOB_ID"
$FLINK_HOME/flink cancel $JOB_ID
else
echo "No running Flink jobs found."
fi
echo "2-2. Close Flink"
close_process "flink"
##3. hbase
echo "3. Close Hbase"
sudo ${HBASE_HOME}/stop-hbase.sh
##4.end
echo "Close Well Done"
'프로젝트 > Pinpoint, Scouter 구축(APM)' 카테고리의 다른 글
| [포팅 메뉴얼] 스카우터(Scouter), 핀포인트(Pinpoint) 설치 가이드 - 1 (0) | 2024.04.05 |
|---|---|
| [Github Action] 배포 환경 구축 (0) | 2024.02.06 |
| [비공개][포팅 메뉴얼] 스카우터(Scouter), 핀포인트(Pinpoint) 설치 가이드 - 1 (2) | 2024.02.01 |
| [Pinpoint - plugin]DB 추적 이슈 : tomcat 서버(Agent)와 DB 서버가 다를 때 (0) | 2024.01.30 |
| flink - java.net.UnknownHostException / 이름 혹은 서비스를 알 수 없습니다. (1) | 2024.01.30 |



