개요
HikariCP는 고성능 JDBC 커넥션 풀 라이브러리로, Spring Boot에서 널리 사용되며, DB 연결 관리를 최적화하기 위해 설계되었다.
Spring Boot는 HikariCP를 기본적인 DataSource 구현체로 사용한다. (Spring Boot 2.0 이상 버전부터 HikariCP가 기본 Connection Pool로 설정되어 있다.)
이는 Spring Boot의 자동 구성 메커니즘을 통해 제공되며, 특별한 설정 없이도 HikariCP를 사용할 수 있게 해준다. 사용자는 application.properties 또는 application.yml 파일에서 HikariCP에 대한 세부 설정을 조정할 수 있다.
HikariCP는 JDBC의 javax.sql.DataSource 인터페이스를 구현한다.
DataSource 인터페이스는 데이터베이스 연결을 얻기 위한 표준 방법을 제공하며, HikariCP는 이 인터페이스를 구현하여 데이터베이스 연결 풀을 관리한다. 따라서, HikariCP를 통해 생성된 DataSource는 javax.sql.DataSource 인터페이스를 준수하며, 이를 통해 데이터베이스 연결을 얻고 SQL 쿼리를 실행할 수 있다.
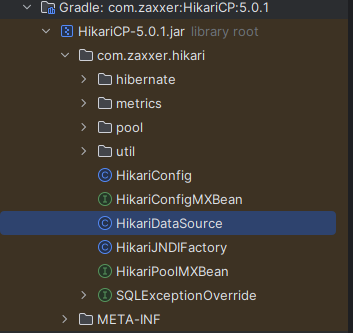

각 패키지는 무슨 역할을 하는가?
com.zaxxer.hikari
HikariCP의 핵심 패키지로, 커넥션 풀 관리, 설정, 커넥션의 생성 및 반환 등을 담당하는 클래스들이 위치한다. HikariDataSource 클래스가 이 패키지에 속해 있으며, 애플리케이션에서 직접 사용되는 주요 진입점이다.
com.zaxxer.hikari.pool
이 패키지는 커넥션 풀의 핵심 기능을 구현한다. 여기에는 커넥션 풀의 생성, 커넥션의 할당 및 반환, 커넥션 상태 관리 등이 포함된다. HikariPool 클래스는 풀의 상태를 관리하며, 커넥션 요청이 있을 때 사용 가능한 커넥션을 제공하거나 필요한 경우 새로운 커넥션을 생성한다.
com.zaxxer.hikari.hibernate
Hibernate ORM과 HikariCP를 통합하기 위한 클래스들을 포함한다. Hibernate는 JPA(Java Persistence API)의 구현체 중 하나로, 데이터베이스와 객체 지향 프로그래밍 사이의 매핑을 쉽게 해주는 프레임워크다. HikariCP를 Hibernate와 함께 사용하려면 이 패키지의 통합 코드가 필요할 수 있다.
com.zaxxer.hikari.metrics
이 패키지는 HikariCP의 성능 모니터링 및 메트릭스(지표) 수집 기능을 제공한다. 커넥션 풀의 상태, 활성 커넥션 수, 대기 시간 등 다양한 성능 지표를 수집하고 분석할 수 있도록 돕는다. 이를 통해 애플리케이션의 데이터베이스 연결 성능을 모니터링하고 최적화할 수 있다.
com.zaxxer.hikari.util
유틸리티 클래스들이 위치하는 패키지로, 커넥션 풀의 설정, 로깅, 스레드 관리 등 다양한 보조 기능을 제공한다. 이 패키지의 클래스들은 HikariCP의 내부 작업을 지원하며, 풀 관리와 관련된 보조 작업을 담당한다.
pool Package
Connection Pool
Connection Pool은 데이터베이스와의 연결을 재사용 가능한 형태로 관리하는 컴포넌트다.
애플리케이션에서 데이터베이스 연결이 필요할 때마다 새로운 연결을 생성하는 대신, 미리 생성해둔 연결 집합(풀)에서 연결을 빌려 사용하고 작업이 끝난 후 다시 풀에 반환하는 방식으로 동작한다. 이 접근 방식은 연결 생성 및 종료에 따른 오버헤드를 줄이고, 시스템 자원을 효율적으로 사용하며, 데이터베이스 연결 시간을 단축시킨다.
Connection Pool의 핵심 기능은 다음과 같다:
- 연결의 재사용: 이미 생성된 연결을 재사용함으로써 연결/종료에 소모되는 시간과 자원을 절약한다.
- 연결의 제한: 동시에 사용할 수 있는 데이터베이스 연결 수를 제한하여 시스템 자원을 보호한다.
- 연결의 관리: 유효하지 않거나 오래된 연결을 자동으로 감지하고 종료한다.
- 연결 할당: 요청에 따라 적절한 연결을 할당하고 사용 가능한 상태로 유지한다.
- 부하 분산: 연결 요청이 많을 때 부하를 분산시켜 성능 저하를 방지한다.
pool Package 세부 구성 요소
그렇기에, 실제 DB에 접근할 수 있는 것은 ConnctionPool과 직접적으로 관련된 'pool' 패키지일 것이다.
대부분 Proxy 객체들로 구성 요소가 이루어져 있으며, Pool의 생성과 커넥션을 관리하는 것으로 보인다.
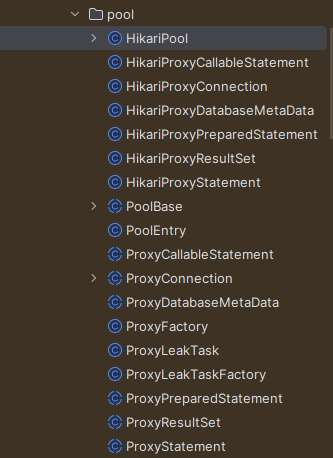
이는 Proxy 객체를 통해 지연 로딩, 혹은 참조를 통한 실제 구현체로의 전달값을 보낸다는 것을 의미한다고 유추했다.
이 코드들에 바이트코드 조작을 한다면, 실 SQL 쿼리를 뽑아낼 수 있을 것이다.
찾아본 결과, 대표적으로 다음 클래스들이 존재했다.
- HikariProxyConnection: 실제 Connection 객체를 감싸는 프록시로, 커넥션 풀로부터 커넥션을 할당받거나 반환할 때 추가적인 로직을 실행한다.
- HikariProxyPreparedStatement: PreparedStatement 객체의 프록시로, SQL 쿼리 실행 전후에 추가 로직을 제공한다.
- HikariProxyStatement: Statement 객체의 프록시로, SQL 명령어를 데이터베이스에 전달하는 기본 인터페이스를 감싼다.
- HikariProxyResultSet: ResultSet 객체의 프록시로, 데이터베이스 쿼리 결과를 순회하고 처리하는 데 필요한 로직을 추가한다.
- HikariProxyCallableStatement: CallableStatement 객체의 프록시로, 데이터베이스에 저장된 프로시저를 호출할 때 사용된다.
여기서 JDBC의 동작 과정을 다시 고찰해보자. (조작 지점 확인)
실제 JDBC에서는 동작 과정이 다음과 같은 형태로 이루어진다.
- DataSource 구현체들은 데이터베이스 연결을 추상화하고, 특정 데이터베이스와의 연결을 생성하기 위한 메소드를 제공한다.
각 구현체는 내부적으로 다양한 로직을 가질 수 있으나, javax.sql.DataSource 인터페이스를 구현함으로써 일관된 방식으로 연결을 관리할 수 있다. - Connection 객체를 통해 쿼리를 데이터베이스에 전송한다. PreparedStatement는 파라미터화된 SQL 쿼리를 효율적으로 실행하기 위한 인터페이스를 제공하며, execute(), executeQuery(), executeUpdate() 등의 메소드를 사용하여 쿼리를 실행한다.
- executeQuery() 메소드는 ResultSet 객체를 반환하여 쿼리 결과를 나타낸다. 이 객체를 통해 결과 데이터를 순회하고 읽을 수 있다.
즉, 우리는 HikariCP의 PreparedStatement 구현체의 execute() 등의 실행 메서드에 접근해서 바이트코드 작업을 수행해야 한다.
statement를 상속받는 유사한 클래스들 (구체적 조작 지점)
executeQuery() 등 로깅을 통해 진행하려고 하는데, 유사한 클래스가 다수 보인다. 'HikariProxyPreparedStatement', 'HikariProxyStatement', 'ProxyStatement' ..
HikariProxyPreparedStatement를 먼저 사용할 것이다. 이는 'ProxyPrearedStatement'를 상속한 자식이며, pstmt의 구현체이다.
더 구체적으로 말하면 HikariProxyPreparedStatement는 HikariCP가 제공하는 구체적인 프록시 클래스이며, ProxyPreparedStatement는 HikariProxyPreparedStatement의 기능을 제공하는 추상 클래스이다.
일반적으로 preparedStatement를 사용하니(동일한 쿼리를 캐싱하기에, pstmt가 일반적으로 효율이 높다.)
https://webstone.tistory.com/56
Statement와 PreparedStatement의 차이점
일단 Statement와 PreparedStatement의 차이점을 알기 전에 prepared Statement가 무엇인지에 대해 알아보자. PreparedStatement란:데이터베이스 관리 시스템(DBMS)에서 동일하거나 비슷한 데이터베이스 문을 높은
webstone.tistory.com
이쪽 부분에 로깅을 진행해보겠다.
(그러나, Statement를 사용하는 경우도 있기 때문에 이에 대한 로깅도 필요할 수 있다. 예를 들어, 정적인 SQL 문을 실행할 때는 해당 구현체(ProxyStatement)를 사용할 수도 있다.)
package com.zaxxer.hikari.pool;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.SQLWarning;
import java.sql.Statement;
import java.sql.Wrapper;
public final class HikariProxyStatement extends ProxyStatement implements Wrapper, AutoCloseable, Statement {
public boolean isWrapperFor(Class var1) throws SQLException {
try {
//이런 부분에 바이트코드 조작을 실행하면 될 것이다.
return super.delegate.isWrapperFor(var1);
} catch (SQLException var3) {
throw this.checkException(var3);
}
}
public ResultSet executeQuery(String var1) throws SQLException {
try {
return super.executeQuery(var1);
} catch (SQLException var3) {
throw this.checkException(var3);
}
}
.. 생략
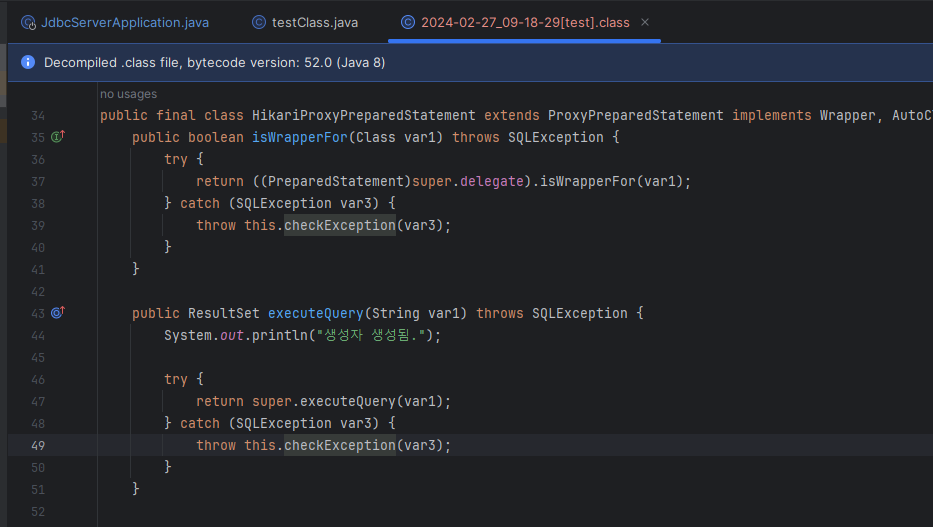
이를 바이트코드 조작을 통해 간단한 로깅을 추가하였다.
public final class HikariProxyPreparedStatement extends ProxyPreparedStatement implements Wrapper, AutoCloseable, Statement, PreparedStatement {
public boolean isWrapperFor(Class var1) throws SQLException {
try {
return ((PreparedStatement)super.delegate).isWrapperFor(var1);
} catch (SQLException var3) {
throw this.checkException(var3);
}
}
public ResultSet executeQuery(String var1) throws SQLException {
System.out.println("생성자 생성됨.");
try {
return super.executeQuery(var1);
} catch (SQLException var3) {
throw this.checkException(var3);
}
}
package org.sch.asm_tree_api;
import org.objectweb.asm.Type;
import org.objectweb.asm.tree.*;
import java.util.Arrays;
import java.util.Iterator;
import static org.objectweb.asm.Opcodes.*;
public class AddLogger {
public AddLogger(ClassNode cn) {
Iterator<MethodNode> iterator = cn.methods.iterator();
while (iterator.hasNext()) {
MethodNode methodNode = iterator.next();
Type[] argumentTypes = Type.getArgumentTypes(methodNode.desc); //MethodNode의 입력 타입, void일 경우 Null
if (methodNode.name.contains("execute") && argumentTypes.length > 0) {
InsnList il = new InsnList();
il.add(new FieldInsnNode(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;"));
il.add(new LdcInsnNode("생성자 생성됨."));
il.add(new MethodInsnNode(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false));
methodNode.instructions.insert(il); //return보다 앞서서 메서드 맨 위에 지시문 추가.
}
}
}
}
문제 상황과 원인 분석 : 클래스로더 실행 시점(생명주기)
이는 잘못된 판단이었으니, 정정한다. 정확히 말하자면 Pstmt가 아니라 HikariProxyResultSet가 주로 호출되는 이슈이다. 이것의 원인은 JPA 및 고수준 추상화에서는 pstmt를 자주 호출하기 않기 때문이다.
(자체적으로 효율을 위해 ResultSet만 호출하는 것으로 추정중)
기대대로라면 정상적으로 SQL CRUD 진행 시 콘솔 출력이 나와야 하지만, 나오지 않았다.
바이트코드 조작 자체는 성공적으로 이루어졌다고 판단했다. 문제로 유추되는 사항은 이것이다.
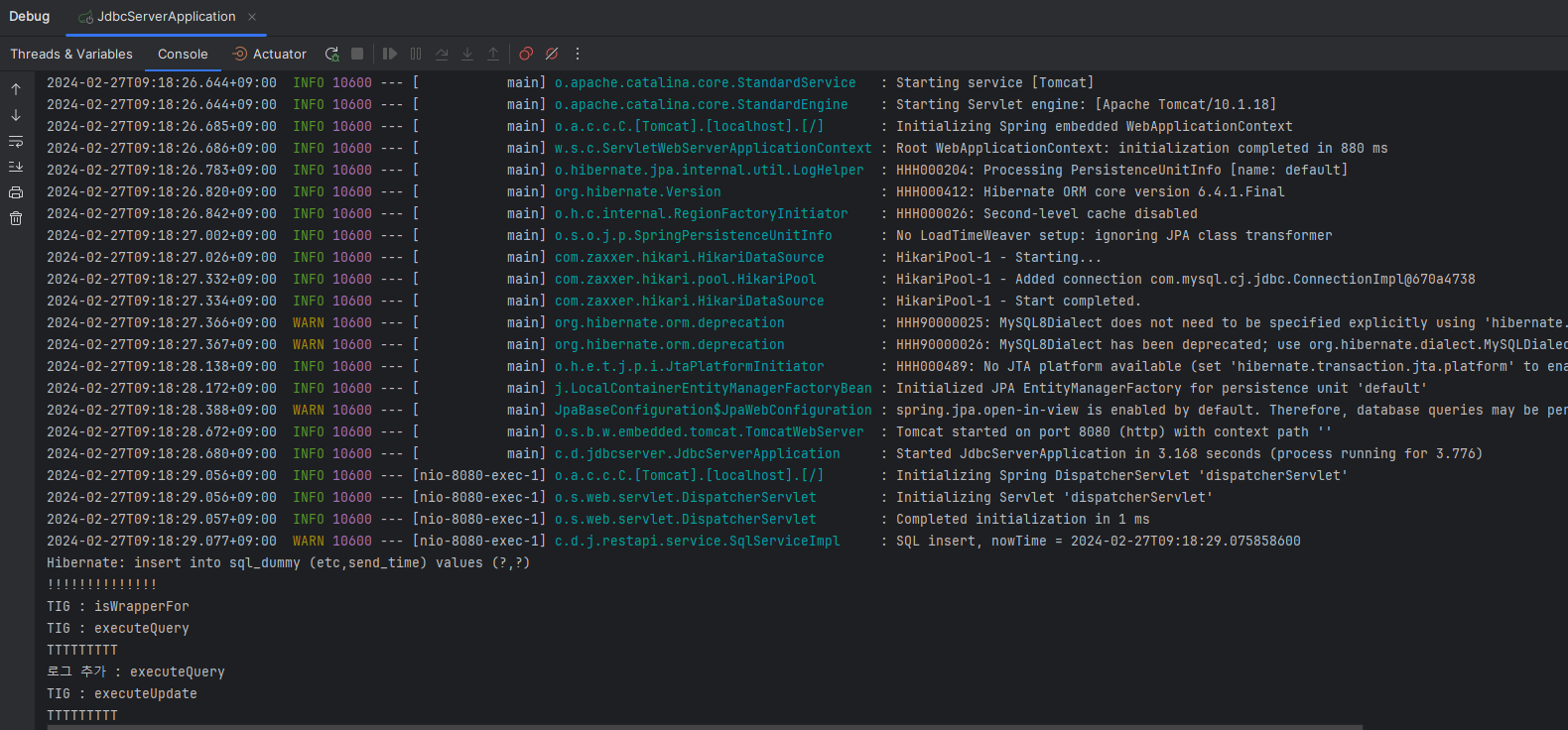
내 스프링 서버의 run 콘솔 창 중 일부이다.
2024-02-27T09:18:27.002+09:00 INFO 10600 --- [ main] o.s.o.j.p.SpringPersistenceUnitInfo : No LoadTimeWeaver setup: ignoring JPA class transformer
2024-02-27T09:18:27.026+09:00 INFO 10600 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
2024-02-27T09:18:27.332+09:00 INFO 10600 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@670a4738
2024-02-27T09:18:27.334+09:00 INFO 10600 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
2024-02-27T09:18:27.366+09:00 WARN 10600 --- [ main] org.hibernate.orm.deprecation : HHH90000025: MySQL8Dialect does not need to be specified explicitly using 'hibernate.dialect' (remove the property setting and it will be selected by default)
2024-02-27T09:18:27.367+09:00 WARN 10600 --- [ main] org.hibernate.orm.deprecation : HHH90000026: MySQL8Dialect has been deprecated; use org.hibernate.dialect.MySQLDialect instead
2024-02-27T09:18:28.138+09:00 INFO 10600 --- [ main] o.h.e.t.j.p.i.JtaPlatformInitiator : HHH000489: No JTA platform available (set 'hibernate.transaction.jta.platform' to enable JTA platform integration)
2024-02-27T09:18:28.172+09:00 INFO 10600 --- [ main] j.LocalContainerEntityManagerFactoryBean : Initialized JPA EntityManagerFactory for persistence unit 'default'
2024-02-27T09:18:28.388+09:00 WARN 10600 --- [ main] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
2024-02-27T09:18:28.672+09:00 INFO 10600 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path ''
2024-02-27T09:18:28.680+09:00 INFO 10600 --- [ main] c.d.jdbcserver.JdbcServerApplication : Started JdbcServerApplication in 3.168 seconds (process running for 3.776)
2024-02-27T09:18:29.056+09:00 INFO 10600 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2024-02-27T09:18:29.056+09:00 INFO 10600 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2024-02-27T09:18:29.057+09:00 INFO 10600 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 1 ms
2024-02-27T09:18:29.077+09:00 WARN 10600 --- [nio-8080-exec-1] c.d.j.restapi.service.SqlServiceImpl : SQL insert, nowTime = 2024-02-27T09:18:29.075858600
Hibernate: insert into sql_dummy (etc,send_time) values (?,?)
!!!!!!!!!!!!!!
TIG : isWrapperFor
TIG : executeQuery
TTTTTTTTT
로그 추가 : executeQuery
TIG : executeUpdate
SpringBoot Run 실행 시 콘솔 동작 중 일부이다. 'HikariPool-1 - Start completed.' 이후 아래의 콘솔 로그가 뜨는 것으로 보아 이미 커넥션이 일어난 이후 바이트코드 변조가 이루어지는 것으로 추측된다.
즉, 1. Premain 시행 -> 2. SpringBoot(Hikari Connect) -> 3. 바이트코드 변조 시행의 과정을 거친다는 것이다.
이를 좀더 자세히 알아보고자 로깅을 추가하여 분석하였다. ClassFileTransformer 구현체가 클래스를 읽으면, 이름을 출력하게 하였다.
@Slf4j
public class TestClassTransformer implements ClassFileTransformer {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
log.warn("[TRANSFORM] CLASSNAME : {}", className);
return classfileBuffer;
}
}
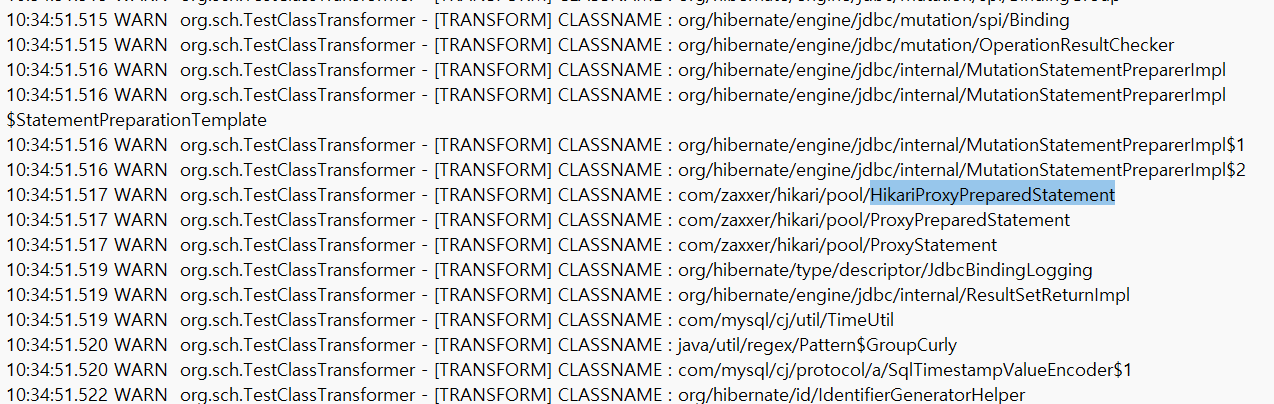

이것이 핵심 원인이다. ClassFileTransformer가 transform을 수행함과 동시에, Tomcat(SpringBoot Embedded)은 별도로 부트를 동작하는 것 같다.
10:34:49 : HikariPool Build -> 10:34:51 : Hikari Class File read
즉, 문제의 핵심은 Spring Boot 애플리케이션의 초기화 및 클래스 로딩 과정 중에 Agent를 통한 클래스 변조가 원하는 시점에 이루어지지 않는다는 점이다.
원하는 조건은 HikariCP Connection Pool이 초기화되기 전에 특정 클래스를 변조하는 것인데, 실제로는 Tomcat이 구동되는 과정에서 클래스 변조가 이루어져 이를 원하는 시점에 맞추기 어렵다는 문제 상황이다.
해결 방법
글이 길어져서 타 포스팅으로 대체한다.
번외)해결 방법 : 프록시 사용?
@Configuration
public class DataSourceConfig {
private final DataSourceProperties properties;
public DataSourceConfig(DataSourceProperties properties) {
this.properties = properties;
}
@Bean
@Primary
public DataSource dataSource() {
// DataSourceProperties를 사용하여 실제 DataSource 구성 (순환 참조 이슈)
DataSource realDataSource = DataSourceBuilder.create()
.driverClassName(properties.getDriverClassName())
.url(properties.getUrl())
.username(properties.getUsername())
.password(properties.getPassword())
.build();
// 프록시 DataSource 생성 및 반환
return DataSourceProxyHandler.createProxy(realDataSource);
}
}/**
* javax.sql.DataSource 인터페이스를 기반
* DataSource의 getConnection() 메서드 호출을 가로채서,
* 반환되는 Connection 객체에 로깅 등의 추가 작업을 수행할 수 있도록 하는 InvocationHandler 구현체
*/
public class DataSourceProxyHandler implements InvocationHandler {
private final DataSource targetDataSource;
public DataSourceProxyHandler(DataSource targetDataSource) {
this.targetDataSource = targetDataSource;
}
/**
* proxy 인스턴스, 호출된 메서드의 Method 인스턴스, 메서드 전달 인수
1. getConnection 메서드가 호출될 때, 실제 DataSource 객체의 해당 메서드를 호출하여 Connection 객체를 가져온다.
2. 이 Connection 객체에 대한 새로운 프록시를 생성하여 반환한다.
3. 프록시는 Connection 인터페이스의 모든 메서드 호출을 가로채고, prepareStatement 같은 메서드가 호출될 때 SQL 쿼리를 로깅.
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if ("getConnection".equals(method.getName())) {
final Connection connection = (Connection) method.invoke(targetDataSource, args);
// Connection에 대한 프록시를 반환
return Proxy.newProxyInstance(
Connection.class.getClassLoader(),
new Class<?>[]{Connection.class},
(proxyConn, methodConn, argsConn) -> {
//prepareStatement 메서드 호출 시 로깅
if ("prepareStatement".equals(methodConn.getName())) {
System.out.println("SQL proxy 로그: " + argsConn[0]);
}
return methodConn.invoke(connection, argsConn);
});
}
return method.invoke(targetDataSource, args);
}
//DataSource 인스턴스를 받아서, 이를 대리하는 프록시 DataSource 인스턴스를 생성
public static DataSource createProxy(DataSource realDataSource) {
return (DataSource) Proxy.newProxyInstance(
DataSource.class.getClassLoader(),
new Class<?>[]{DataSource.class},
new DataSourceProxyHandler(realDataSource)
);
}
}
이런 식으로, 직접 코드를 조작하는 것이 아니라 동적 프록시를 생성하는 것도 고민해보았다.
이는 간결하고 유연하다는 장점이 있으나, 동시에 높은 오버헤드를 가진다는 치명적인 단점이 존재하여, 사용하지 않았다.
'프로젝트 > APM MiddleWare' 카테고리의 다른 글
| [HikariCP][ASM] JDBC 쿼리 로깅하기(ProxyConnection) (2) | 2024.03.05 |
|---|---|
| [HikariCP][Delegate]ProxyPreparedStatement (0) | 2024.03.04 |
| [ASM][Util]TraceClassVisitor/고수준 코드 출력하기[InteliJ] (0) | 2024.02.23 |
| [A Java bytecode engineering library] - [Tree API] 9.Metadata (0) | 2024.02.23 |
| [ASM] Label 기본 개념 및 if/for/while 제어문 바이트코드 조작 (0) | 2024.02.23 |



