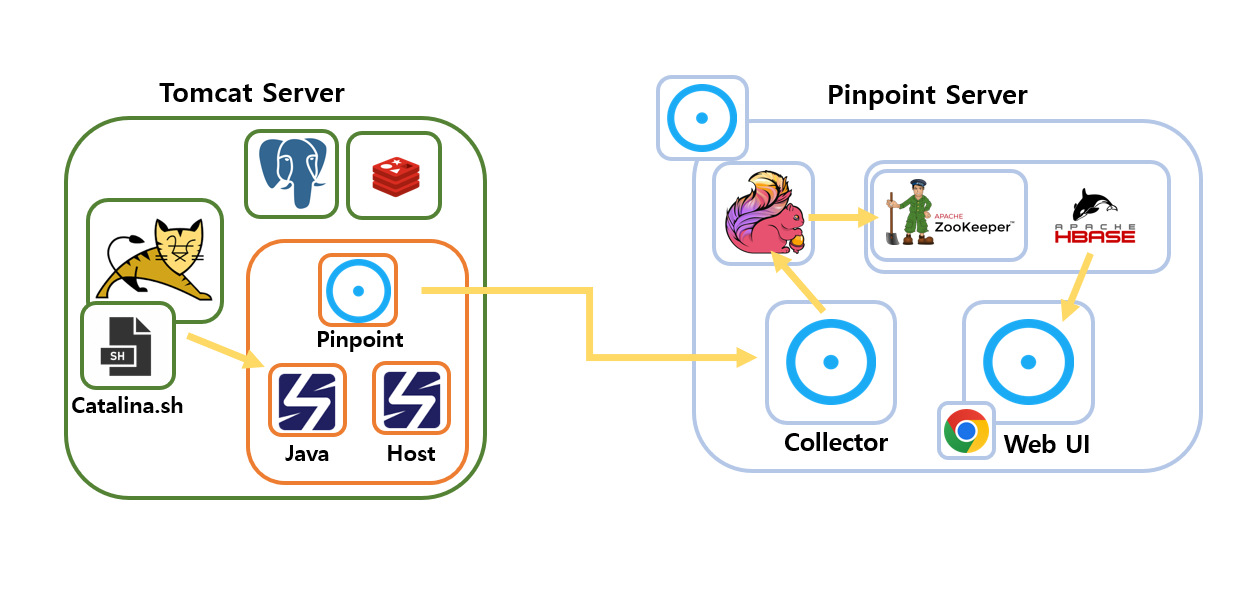
구성 Diagram(Flow)
라이브러리 버전
### OS
centOS 7
openJDK 1.8
### pinpoint
pinpoint : 2.3.3
hbase : 1.4.6
flink : 1.6.3
### scouter
scouter : v2.20.0(latest)
scouter paper : 2.6.4 Latest
구성 환경은 다음과 같다.

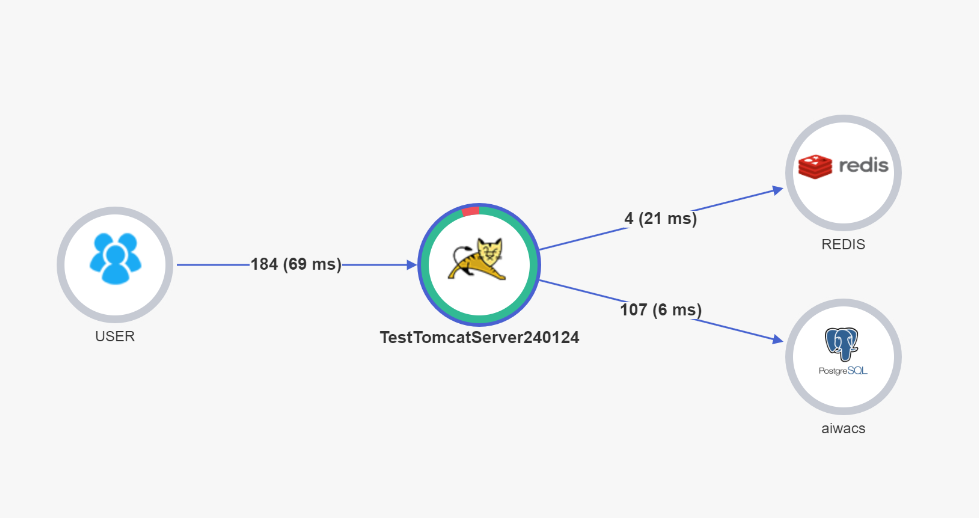
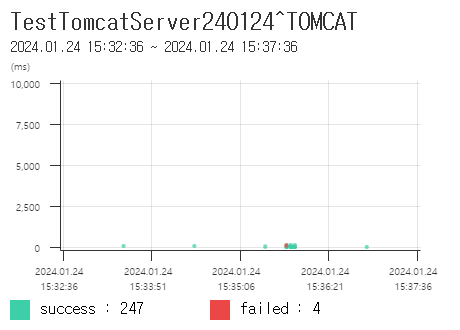
Pinpoint
DashBoard
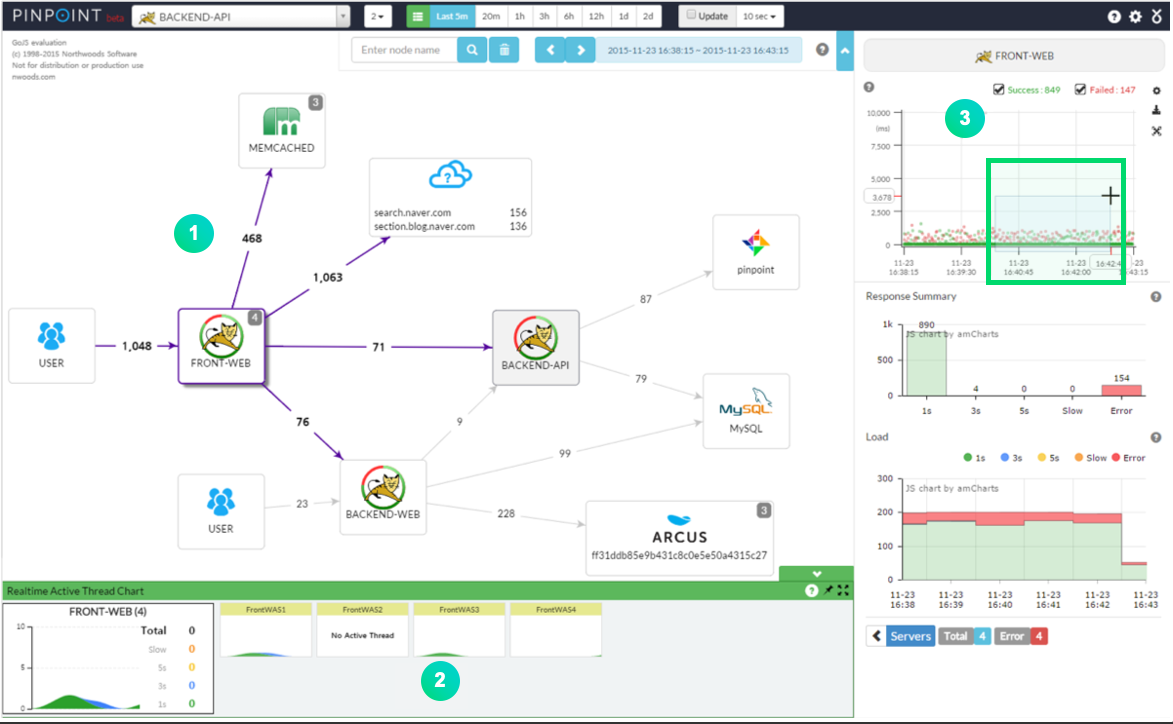
1. Server Map
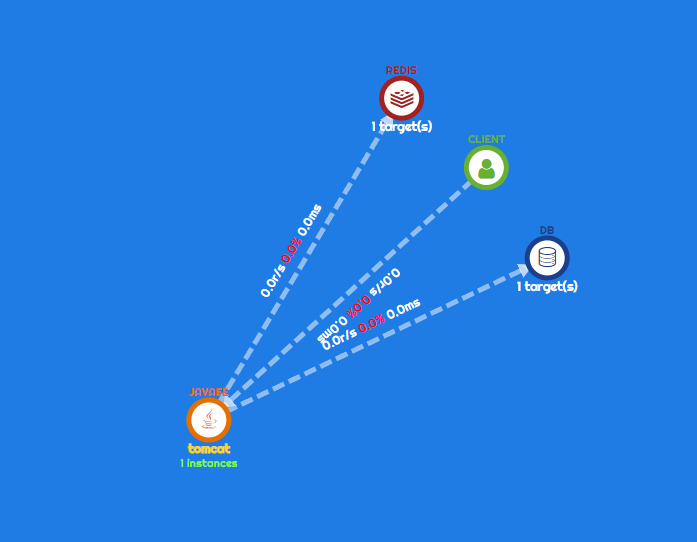
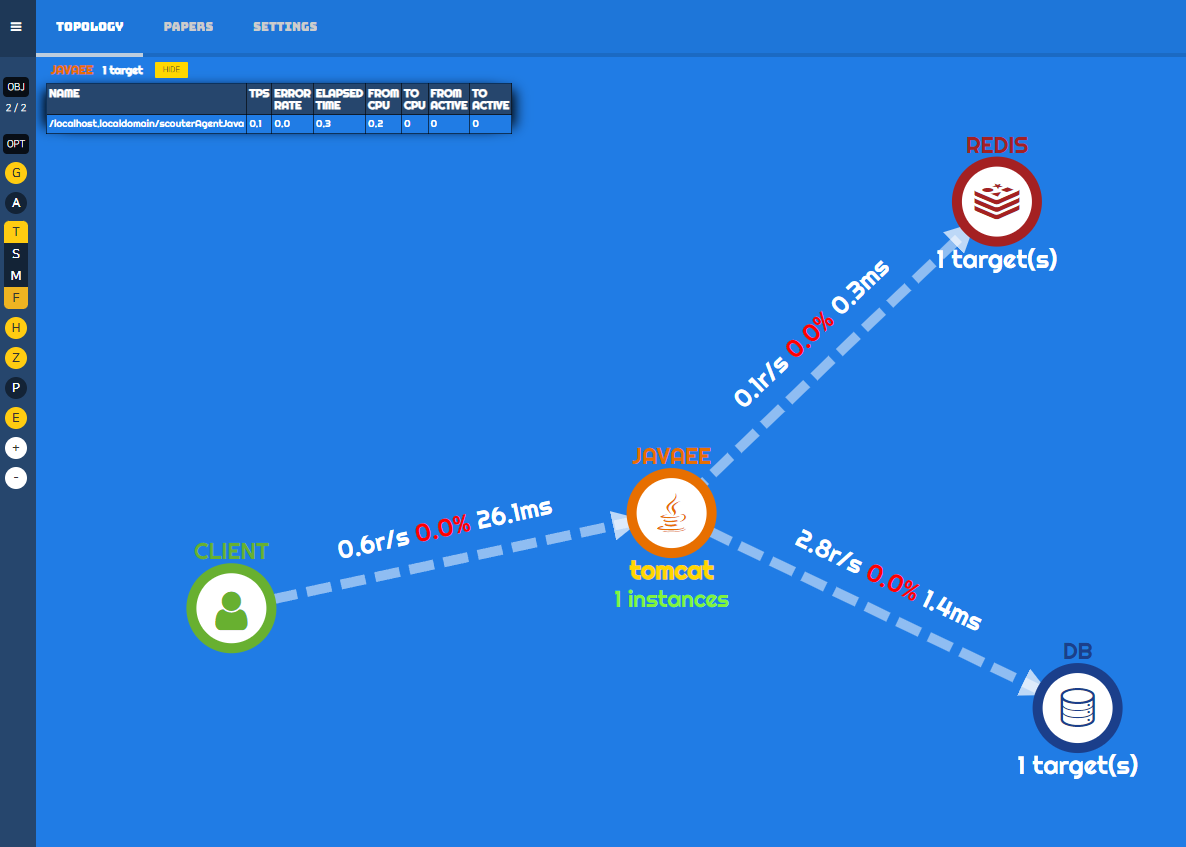
- Dashboard의 형태로 Agent가 심어진 서버와 연관된 모듈간의 Flow 및 흐름 시각화 제공
2. RealTime Active Thread Chart
Active Thread Chart의 경우만 리얼타임이였는데, 1.5.2 version부터 Scatter Chart(3)까지 리얼타임으로 제공하고 있어서 이를 완전히 분리하였다.

- 실시간 Real Time 제공
- 시간별 요청의 CallStack 제공
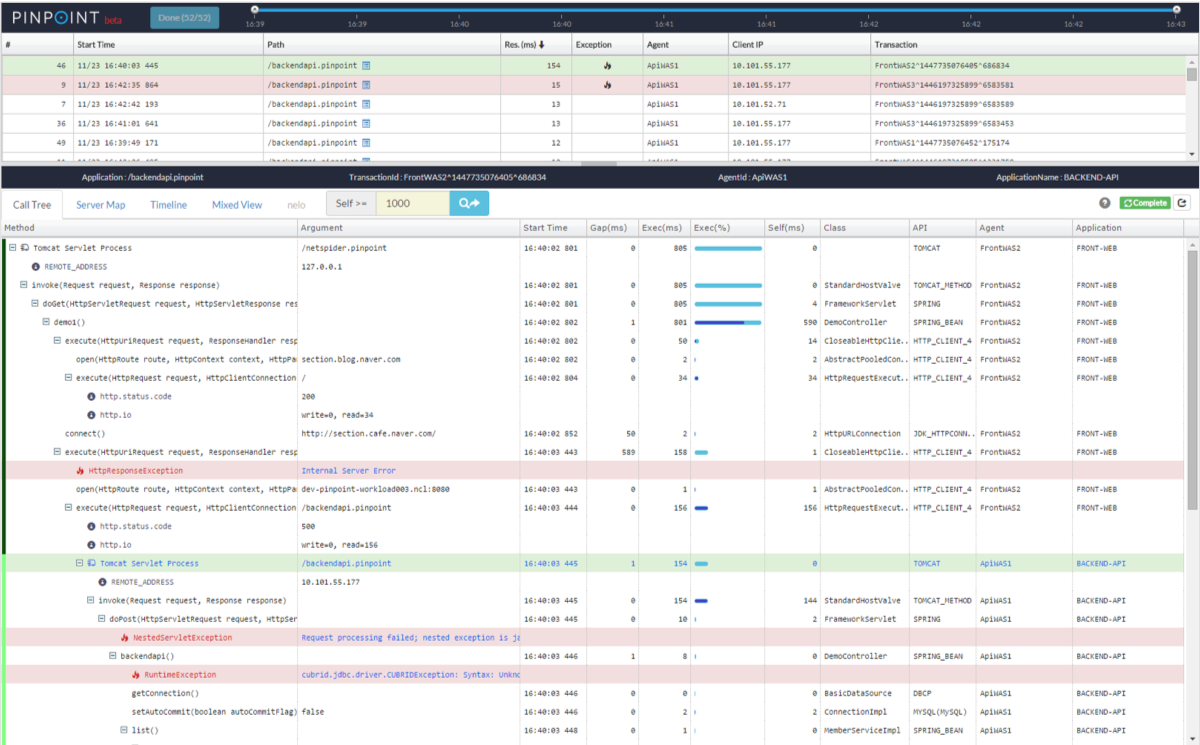
3. Scatter Chart : Request/Response Scatter Chart -> Pinpoint CallStack
RealTime Scatter Graph를 드래그하여 들어가면, Pinpoint CallStack 기능을 사용할 수 있다.
코드 레벨의 트랜잭션 단위 정보를 제공한다.
이를 클릭하여 이 당시에 실행된 구체적 단위의 트랜잭션의 실행 상황을 확인할 수 있다.
Pinpoint Inspector
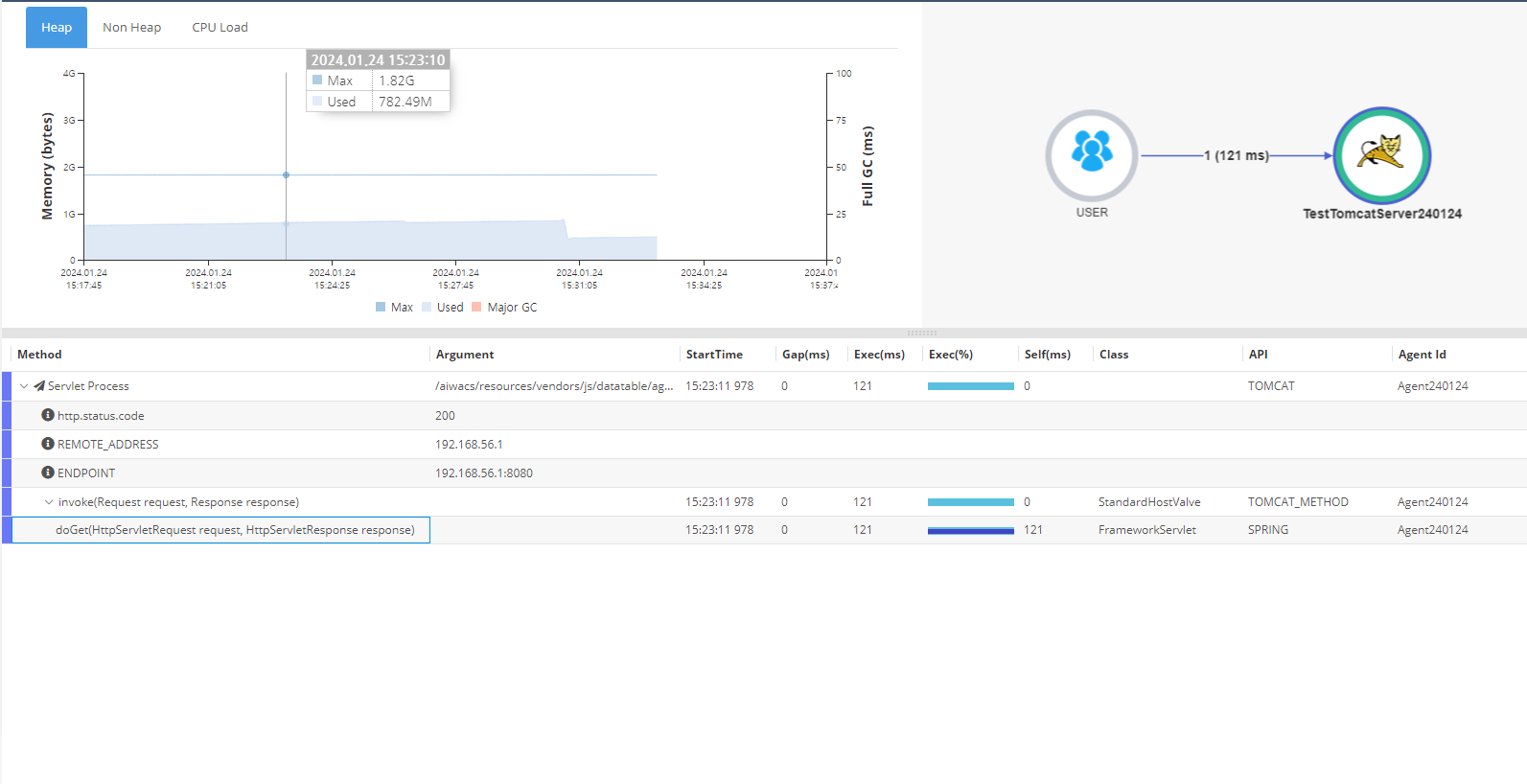
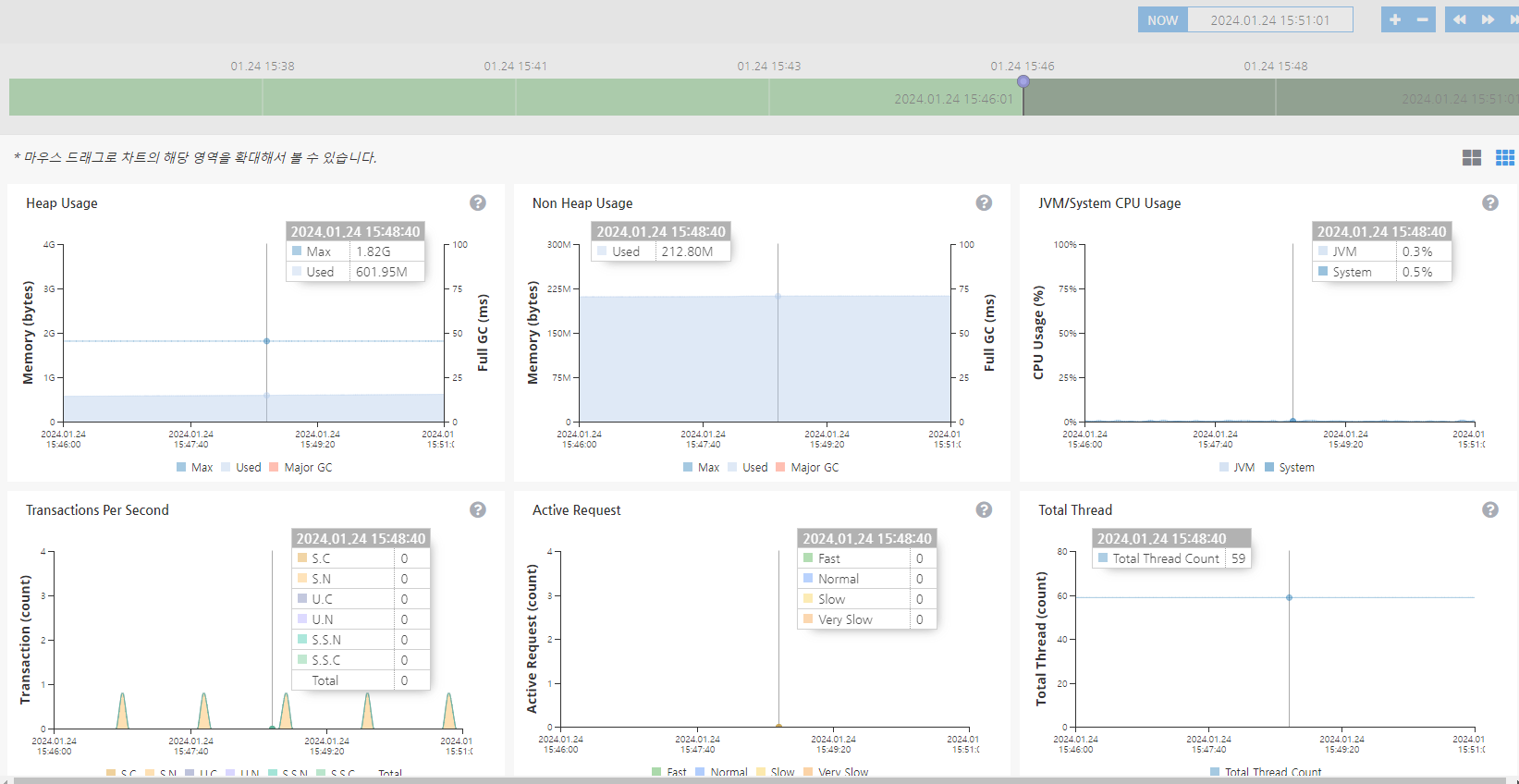
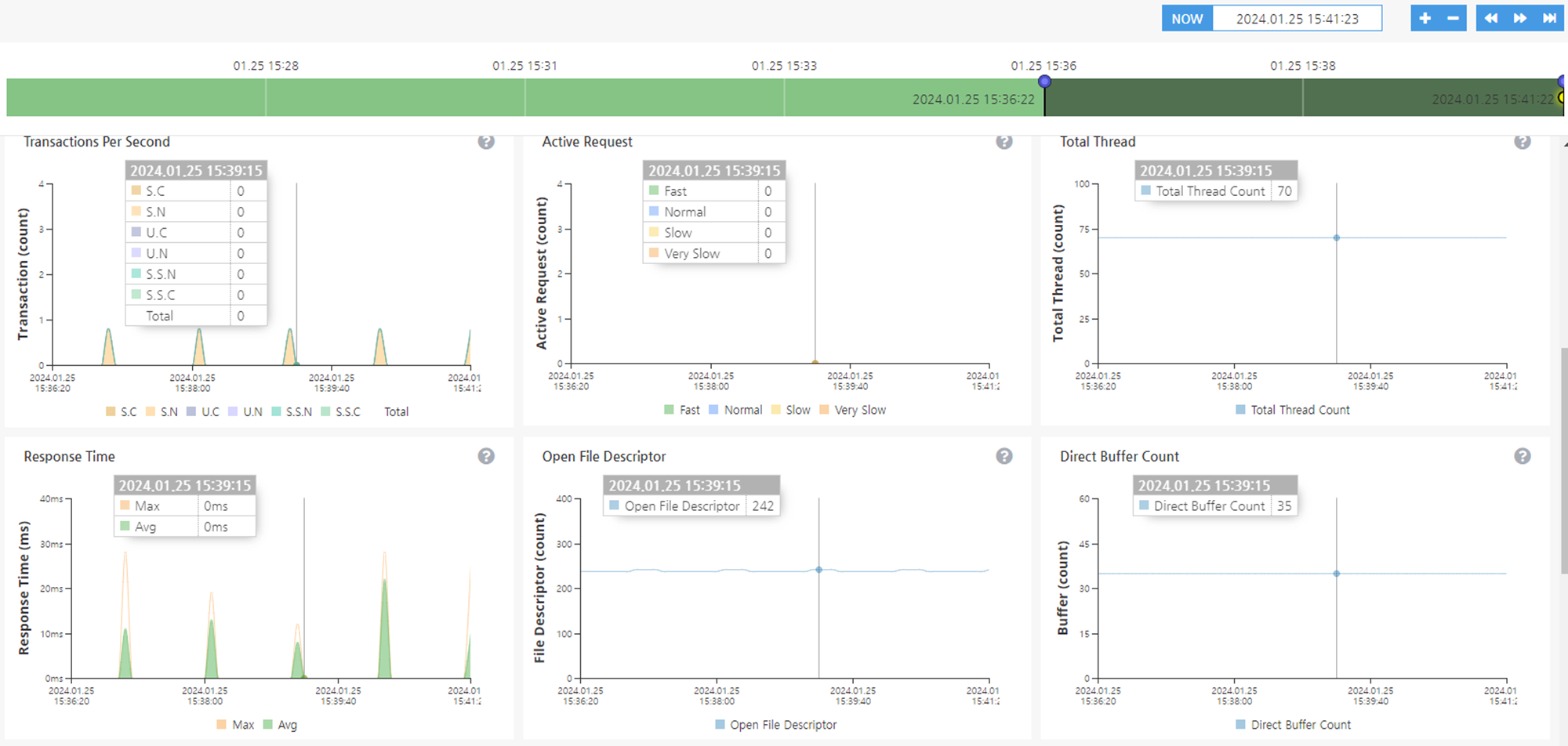
CPU Usage, Memory/Garbage Collection과 같은 부가 정보에 대한 Chart 확인이 가능하다.
구체적으로는 2.3.3 버전 기준으로,
- Head Usage : JVM의 Heap 정보와 Major Garbage Collection 소요 시간
- Non Heap Usage : JVM의 Non-Heap 정보와 Major Garbage Collection 소요 시간
- JVM/System CPU Usage : JVM과 시스템의 CPU 사용량 - 멀티코어 CPU의 경우, 전체 코어 사용량의 평균
- Transactions Per Second : 서버로 인입된 초당 트랜잭션 수
- Active Request : 사용자 Request를 처리하는 Agent의 Active Request 현황
- Total Thread : Agent의 전체 thread 수
- Response Time : Agent의 Response Time
- Open File Descriptor : Agent의 File Descriptor 현황, 현재 열려있는 File Descripter 개수
- Direct Buffer Count : Agent의 Direct Buffer 현황
- Direct Buffer Memory : Agent의 Direct Buffer Memory 현황
- Mapped Buffer Count : Agent의 Mapped Buffer 현황
- Agent에 loading 된 class의 수
의 기능이 존재한다.
Scouter
XLog
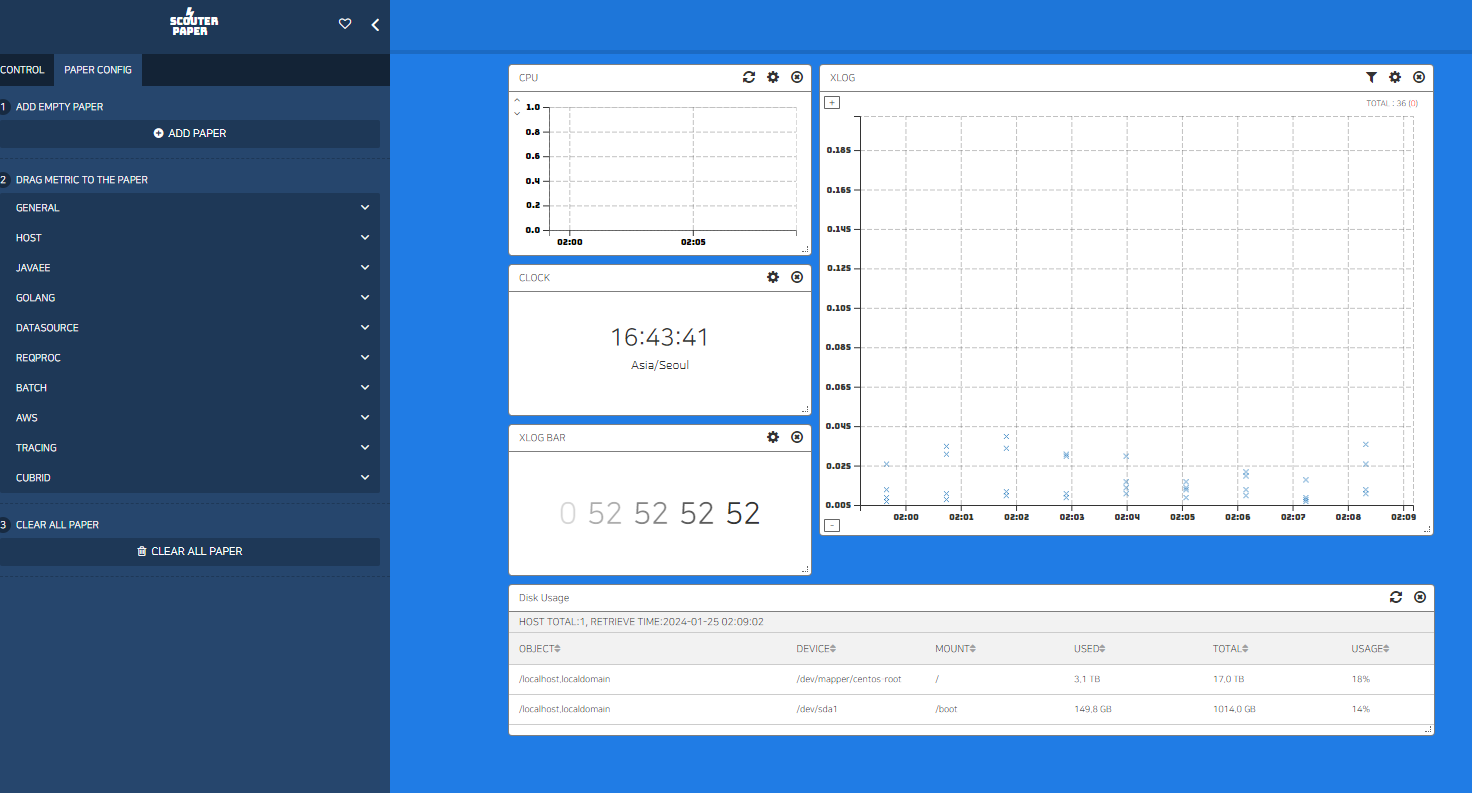
Pinpoint의 Transaction 확인과 유사하게, Scouter에서도 비슷한 기능을 제공한다.
Scouter 에서 응답시간 분포 그래프를 XLog라고 부른다.
XLog는 Transaction Log 라는 의미이다. 전체 트랜잭션을 한눈에 파악할 수 있고, 느린 트랜잭션을 선별하여 조회할 수 있기 때문에 응용 프로그램을 튜닝하는데 가장 효과적인 방법이라 할 수 있다.
Scripting과 Plugins
스크립트와 플러그인을 통한 강력한 부가 기능 제공(추가 예정)
Application 기반 Client와 자유로운 Layout, UI 설정
- 웹 기반이 아닌 애플리케이션 기반 클라이언트로, 상대적으로 경량화 및 빠른 속도를 가진다.
- 구성요소의 배치가 매우 자유롭다. (client 중복 설치, 개별 서버의 그룹핑 등)
또한 Paper를 통한 web 기능도 제공
각각의 장단점
Pinpoint
- 일단 기능이 무지하게 많다. Hbase, Flink 등을 사용하여 대용량 스트림을 제어하고, 보관한다.
이걸 기반으로 엄청나게 많은 정보를 빼오고 데이터시각화하고 .. 자세하고 세밀한 분석을 하는 것이다.
- 특히 MSA나, 분산 환경, 대용량 환경(DB 모체인 Hbase만 봐도..)에 적합한 APM이라고 할 수 있다.
특히, 세밀한 트랜잭션 수준을 볼 수 있는 것은 강력한 장점이다.
Scouter가 쿼리 정도만 볼 수 있다면, Pinpoint는 API 요청 과정에서 구체적으로 어떤 메서드가 실행되는지, 어떤 과정이 시간이 어떻게 되는지.. 구체적으로 알 수 있다.
Scouter
반대로 스카우터의 장점은 '경량화' , 즉 쉽고 빠르게 환경을 구축하며, 상대적으로 가볍라고 할 수 있을 것 같다.
핀포인트는 구축이 정말 힘들었다. 게다가 분산 환경을 고려해서 설계되었기에, 유지보수나 오류 등을 제어하기 정말 힘들 것이다.
또한, 스카우터는 플러그인이나 자체 커스터마이징을 확장에서 제공하는 편이다.
특유의 분야에서 강력함이 느껴지는 효율적인 APM이라는 생각이 많이 들었다.
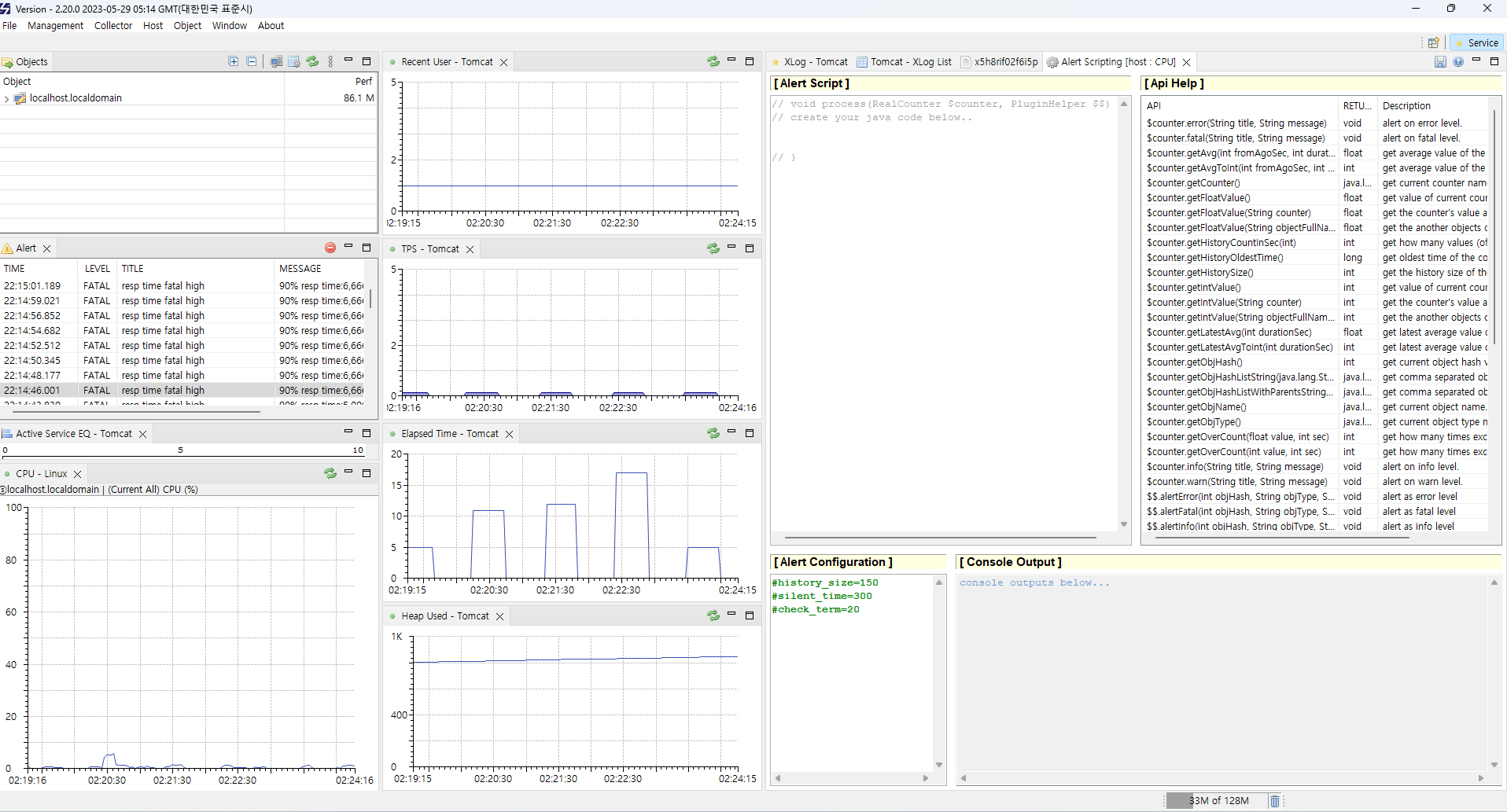
이에 맞춰, 가볍고 소~중규모의 서버라면 적극 스카우터를 권장할 수 있을 것 같다.
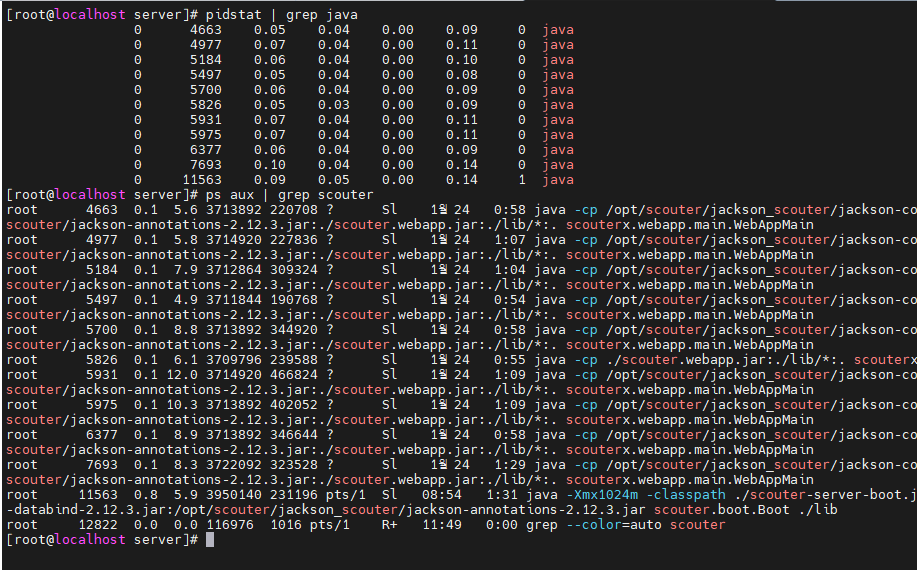
메모리 사용량 비교
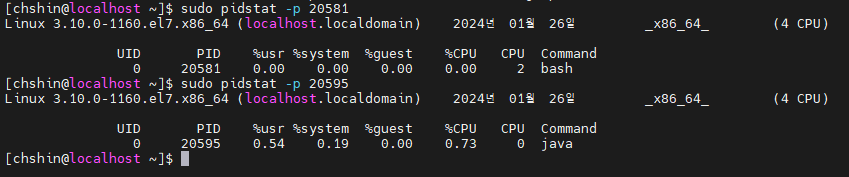
Pidstat을 통해 사용량을 대략적으로 비교해보았다.
pinpoint
pinpoint
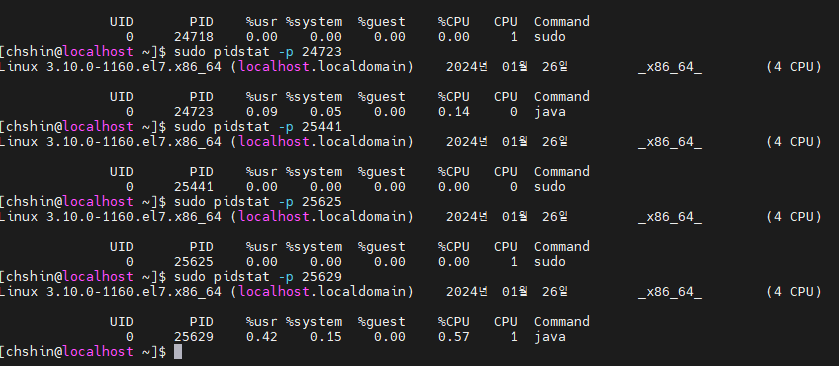
Hbase
Flink
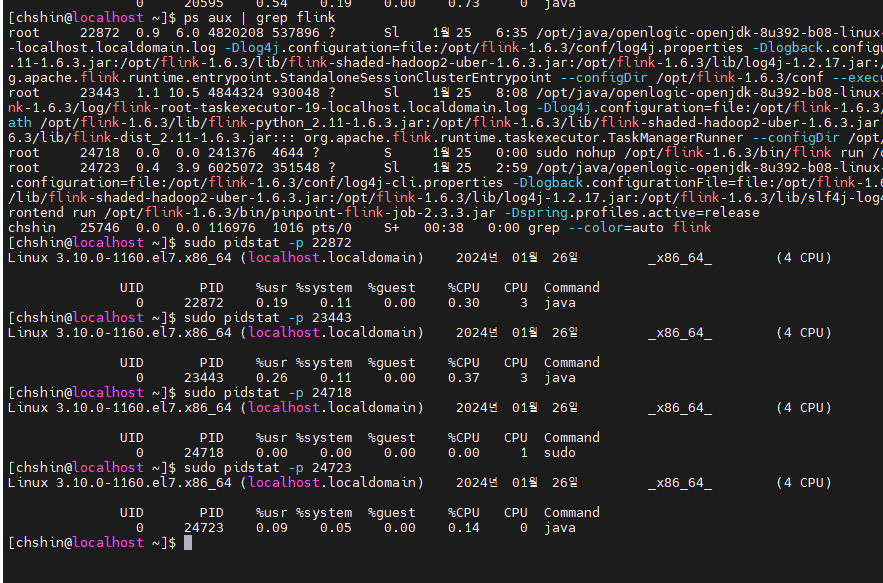
cpu 메모리 사용량 2% ~ 정도..
scouter
핀포인트와 동일 계측 기준 대략 1% 안쪽이다.
물론 자세한 사용량은 이와 차이가 있겠지만, 대략적인 수치만으로도 더 가볍다는 것을 알 수 있다
(핀포인트가 분산 최적화 되어있기 때문에 어찌 보면 당연하기도 하다.)
Reference
Pinpoint
https://guide.ncloud-docs.com/docs/pinpoint-pinpoint-1-2
Pinpoint 시작 가이드
guide.ncloud-docs.com
https://github.com/pinpoint-apm/pinpoint/issues/1842
Realtime Active Thread Chart 활성화시 따로 설정을 해주어야 하나요? · Issue #1842 · pinpoint-apm/pinpoint
pinpoint 1.5.2 버전을 설치하였는데 Realtime Active Thread Chart가 화면에 나타나지 않네요 활성화 하려면 어떻게 해야되나요??
github.com
Scouter
Xlog
https://github.com/scouter-project/scouter/blob/master/scouter.document/client/Reading-XLog_kr.md
서비스 사용 후기
내 서비스에 Scouter APM을 적용해보기
Scouter APM이란? 서비스를 운영하면서 여러가지 요소로 장애를 겪지만, 대부분의 문제는 Applcation입니다. 문제의 원인을 찾는 것은 굉장히 중요한 일입니다. APM은 최종 사용자 에게 향상된 서비스
blog.kingbbode.com



