개요
NoSQL의 경우 일반적으로 RDBMS보다 빠르다고 하는데, 구체적으로 왜 그런지 조사해보았다.
RDBMS(관계형 데이터베이스 관리 시스템)와 NoSQL(비관계형 데이터베이스)은 데이터를 저장하고 관리하는 방식에서 근본적인 차이가 있다.
아래와 같은 이유로 차이가 발생한다.
구조적 차이

SQL의 주요 초점은 데이터 중복을 줄이는 것.
RDBMS의 경우 테이블 형식으로 데이터를 저장하며, 엄격한 스키마를 따른다.
데이터는 행과 열로 구성되며, SQL(Structured Query Language)을 사용하여 데이터를 조작한다.
이를 통해 데이터의 무결성과 일관성, 트랜잭션 등의 규칙을 엄격하게 지킬 수 있다.
NoSQL은 반대로 유연하고 빠른 동적 스키마를 제공한다.
NoSQL 데이터베이스는 비관계형이다.(관계형인 SQL과 반대).
이는 개발자 생산성이 스토리지 비용보다 더 중요해진 2000년대 후반에 처음 등장했다.
NoSQL의 경우 키-값 쌍, 문서, 그래프 등 다양한 데이터 모델을 사용할 수 있으며, 스키마가 유연하거나 없을 수도 있다. NoSQL은 대규모 분산 데이터를 처리하는 데 적합하다.
성능 및 확장성에 대해
RDBMS의 경우 정교한 쿼리와 복잡한 트랜잭션 처리에 강점이 있으나, 대규모 데이터와 고속 처리에는 한계가 있다.
NoSQL은 대규모 데이터 처리와 빠른 읽기/쓰기에 유리하다. 특히 비정형 데이터나 변화하는 데이터 구조에 더 적합하다.
그래서 왜 일반적으로(모든 경우는 아니다.) NoSQL이 빠른가? 구체적인 이유는 다음과 같다.
'조인 등 복잡한 연산이 없다.' , '유연한 구조로 서버 분할이 쉬워, 테이블당 튜플이 많지 않아 검색 속도가 빠르다'
- 스키마 없음
NoSQL 데이터베이스는 스키마가 없거나 유연하다.
이는 데이터를 저장하거나 검색할 때 복잡한 조인 연산이 필요 없다는 것을 의미한다.
SQL 에서는 테이블 간의 관계를 정의하고 유지해야 하므로, 데이터 검색에 더 많은 시간이 소요될 수 있어. - 수평적 확장성
NoSQL 데이터베이스는 수평적으로 확장하기 쉽다.
즉, 서버를 추가하여 데이터베이스의 성능을 향상시킬 수 있다. 반면, 전통적인 SQL 데이터베이스는 수직적 확장(서버의 성능 향상)에 더 의존하는 경향이 있어서, 확장이 더 복잡하다. - 최적화된 쿼리
NoSQL 데이터베이스는 특정 유형의 쿼리에 최적화되어 있을 수 있다.
예를 들어, 문서 지향 데이터베이스는 문서 검색에, 키-값 스토어는 간단한 조회에 빠른 성능을 제공할 수 있다. - 분산 시스템에 적합
많은 NoSQL 데이터베이스가 분산 시스템에 적합하게 설계되어 있다.
이는 데이터를 여러 서버에 분산하여 처리할 수 있으며, 이로 인해 높은 가용성과 병렬 처리 능력을 갖출 수 있어.
내가 사용했던 Elasticsearch에서는 역인덱싱을 제공했다.
역인덱싱(Inverted Indexing)이란?
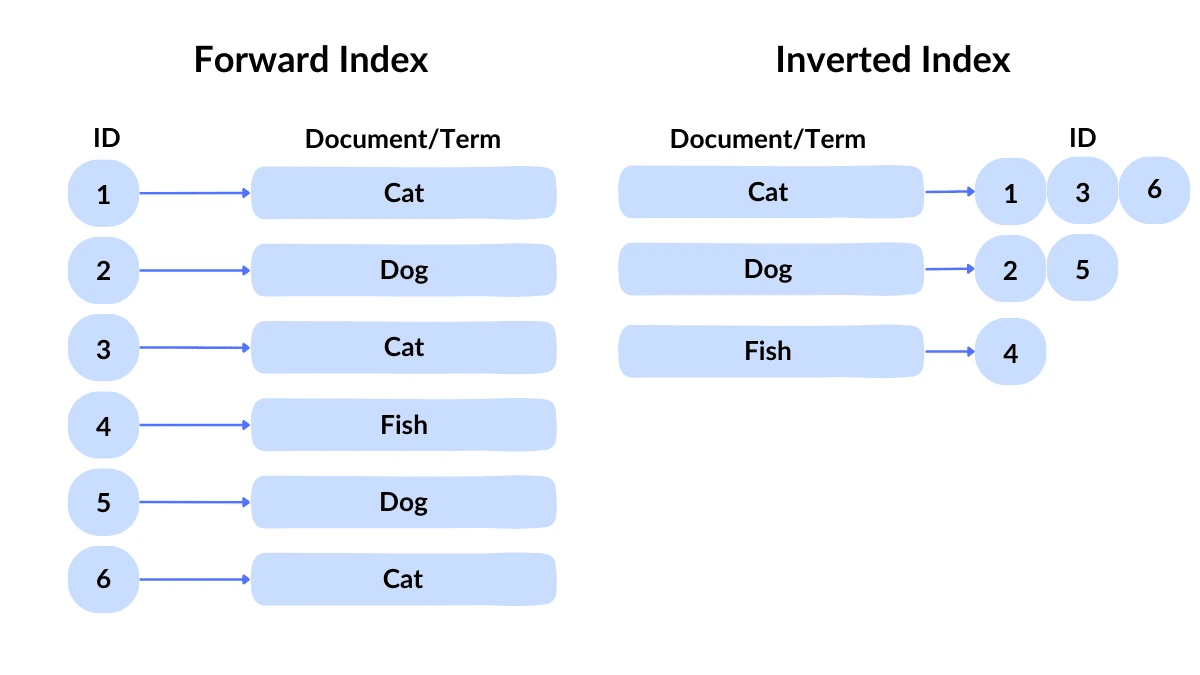
전통적인 인덱스가 'id -> Document' 형식으로 구성되어 있다면, 역인덱싱은 'Document -> id' 형식으로 구성된다. 즉, 각 단어가 어떤 문서에 포함되어 있는지를 나타내는 인덱스를 만드는 것.
이를 통해 사용자가 특정 단어를 검색할 때, 역인덱스는 해당 단어가 포함된 모든 문서를 빠르게 찾을 수 있다.
이는 각 단어가 어떤 문서에 있는지 바로 알 수 있기 때문이다.
역인덱싱 과정
1. 데이터 전처리
1. 토큰화
역색인을 구성하는 첫 번째 단계는 텍스트 데이터를 개별 용어 또는 토큰으로 분해하는 것이다.
2. 단어 제거
'the', 'and', 'in' 등과 같은 일반적인 단어는 중요한 의미를 지니지 않으며 일반적으로 색인 크기를 줄이기 위해 제거된다. ES에서는 분석기의 Filter가 이 역할을 수행했다.
3. 어간 분석/정형화
어떤 경우에는 다음을 보장하기 위해 단어가 어근 형태로 축소됩니다. 단어의 다양한 변화(예: 'run', 'running', 'ran')는 색인에서 동일한 용어로 처리된다. 이는 일반적으로 내가 사용했던 Nori 분석기에서 수행했다.
2. 토큰에 대한 역인덱싱(Inverted Indexing)

각 토큰은 역인덱스에 저장된. 역인덱스는 토큰과 해당 토큰이 포함된 문서의 ID를 매핑한다.
예를 들어, "Java"라는 토큰은 문서 1, 문서 5, 문서 10 등에 포함된다면, 역인덱스는 "Java" -> [문서 1, 문서 5, 문서 10]과 같이 매핑될 것이다.
3. 검색 쿼리 처리
- 사용자가 "Java"라는 단어로 검색을 실행하면, 엘라스틱서치는 역인덱스를 참조해 해당 토큰이 포함된 모든 문서의 ID를 신속하게 찾아낼 수 있다.
- 이를 통해 엘라스틱서치는 대량의 데이터에서도 빠르게 검색 결과를 제공한다.
레퍼런스
https://www.testgorilla.com/blog/sql-vs-nosql/
SQL vs. NoSQL: Full comparison of features, differences, and more
The complete guide to understanding the difference between SQL and NoSQL databases and when to use SQL vs. NoSQL to hire the best developers.
www.testgorilla.com
https://spotintelligence.com/2023/10/30/inverted-indexing/
How To Implement Inverted Indexing [Top 10 Tools & Future Trends]
Inverted index in information retrievalIn the world of information retrieval and search technologies, inverted indexing is a fundamental concept pivotal in
spotintelligence.com
https://www.instaclustr.com/blog/taking-elasticsearch-for-a-spin-around-the-race-track-qa-part-3/
Taking Elasticsearch™ for a Spin around the Race Track (Q&A): Part 3
Paul and Mussa continue their discussion of Elasticsearch internals: Lucene, indexing, sharding, inverted indices, n-grams and APIs.
www.instaclustr.com
'CS study > 데이터베이스' 카테고리의 다른 글
| [인덱스] 순차 증가 값은 항상 효율적인가? (24.06.12) (0) | 2024.10.01 |
|---|---|
| 3주차 - 랜덤I/O, 순차 I/O와 인덱스, B+Tree, B-Tree (0) | 2024.01.25 |
| DataBase 2주차 정리 - SQL, DDL, DML, DCL, JOIN, 쿼리 순서 (0) | 2024.01.18 |
| 1주차 스터디 노트(DB, 스키마, RDBMS, Key, 제약조건) (1) | 2024.01.11 |
| 가볍게 알아보는 인덱스와 성능에 대해(개선예정) (0) | 2023.11.09 |



